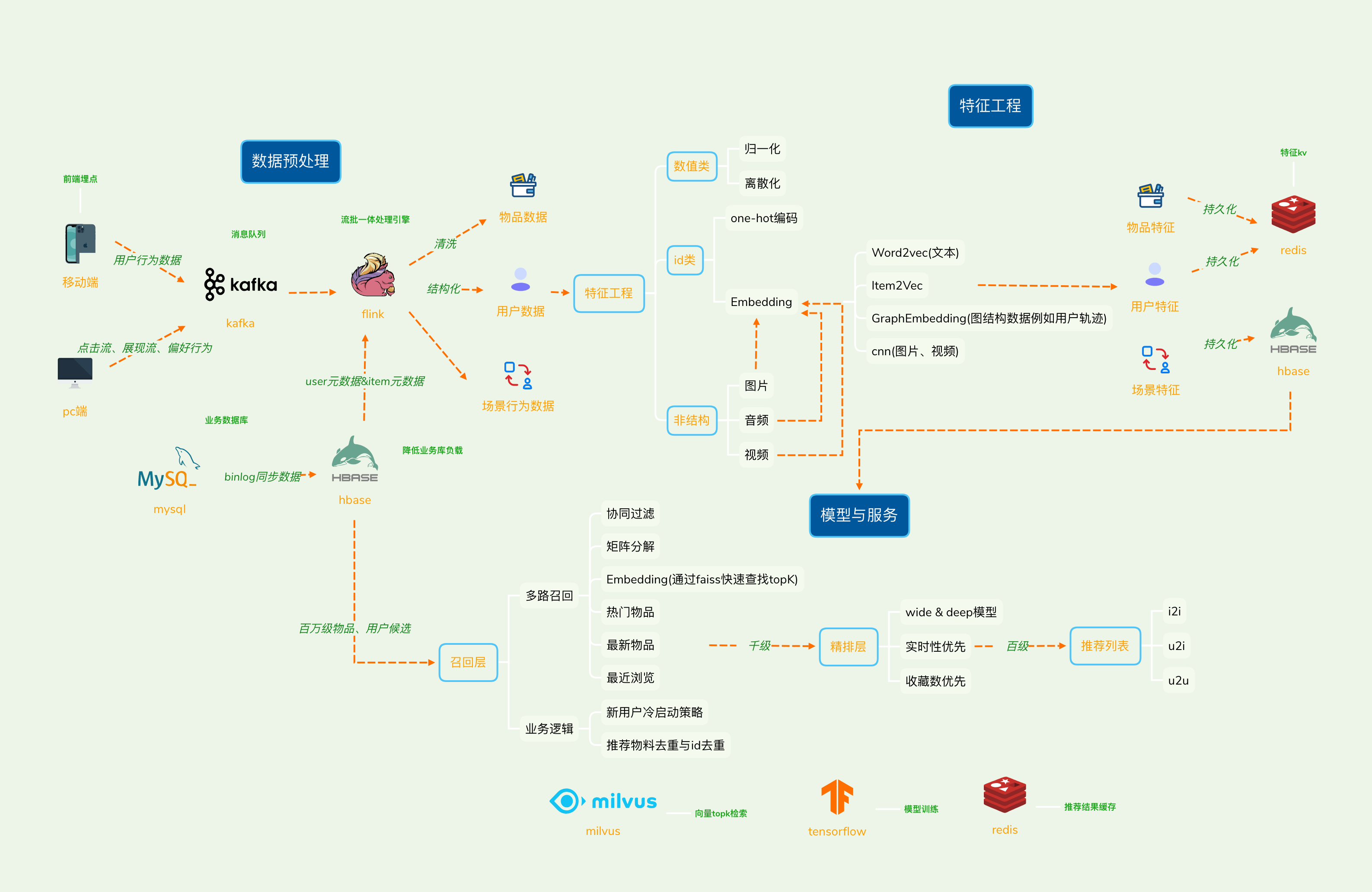
数据预清洗处理
app与网页端添加埋点,发送用户行为至kafka,kafka队列存储行为日志,由flink做抽取结合业务数据库的用户项目元数据进一步处理成用户信息、物品信息、场景信息。清洗过程包括剔除掉脏数据、对数据合法性进行校验、剔除无效字段、字段格式检查等过程。
使用flink做流批一体处理,从日志抽取用户操作行为以及场景信息,从业务数据库抽取用户与物品的属性数据,处理成结构化的推荐系统模型所需的样本数据,用于算法模型的训练和评估。生成推荐系统模型服务所需的“用户特征”,“物品特征”和一部分“场景特征”,用于推荐系统的线上推断。
处理完成后将数据加载至最终的存储,比如数据仓库、关系型数据库、key-value型NoSQL中等。对于离线的推荐系统,训练数据放到数仓中,属性数据存放到关系型数据库(业务数据库)中。
为了降低业务数据库的压力,创建binlog通路,数据实时同步hbase。flink从hbase抽取数据。
特征工程
特征分类
用户
- 偏好标签(可以通过历史偏好物品抽取物品标签)
- 属性标签
- 社交关系
- 轨迹
- 用户行为
物品
- 属性标签
- 元信息
场景
- 时间信息
- 所处页面
特征抽取策略
数值类进行归一化与离散化,分类少的数据进行one-hot编码,非结构化或者分类众多无规则数据进行Embedding,Embedding可以使用Word2vec、Item2Vec、GraphEmbedding等方法。抽取后的特征进入特征数据库,供模型与线上业务使用,Embedding向量同步存储至milvus,利用faiss进行topk邻近向量搜索,kv数据进入redis与hbase。
结构化数据
- 元数据(用户属性、物品属性)中的数值、文本
半结构化数据
- 日志中的行为数据
非结构化数据
- 图片
- 视频
- 音频
- 轨迹
模型
召回
召回层就是要快速、准确地过滤出相关物品,缩小候选集,排序层则要以提升推荐效果为目,作出精准的推荐列表排序。使用多路召回来实现召回层,例如矩阵分解、Embedding向量查找topk邻近向量、热门物品、最近浏览。可以在召回层加入业务强相关的逻辑,例如结合近期浏览的物品,根据物品Embedding召回类似物品。在该层也需要进行冷启动策略、推荐物料去重与id去重等业务逻辑。
精排
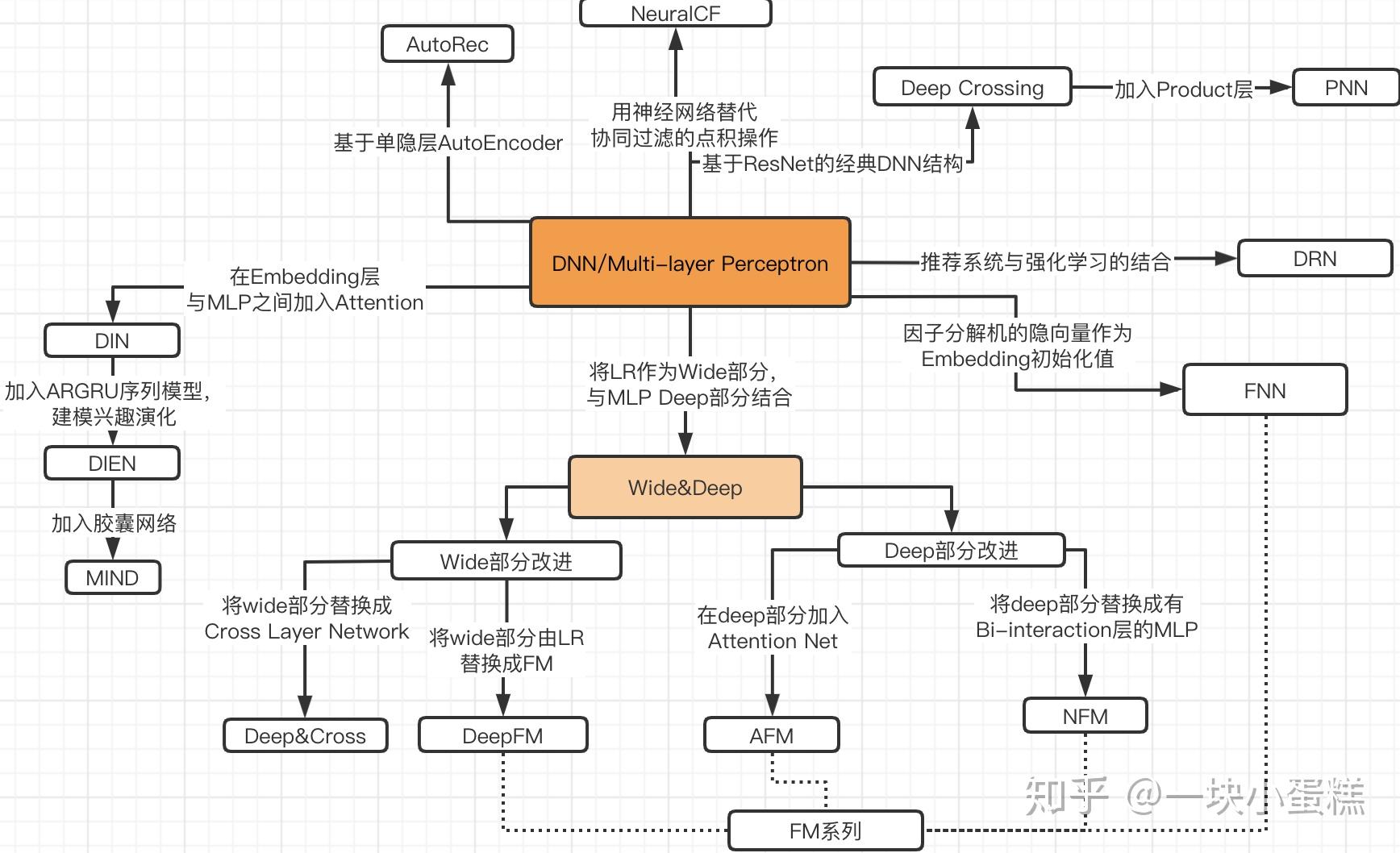
精排层用于讲召回层输出的物品数量级别再降低一个层次,可以利用特征工程产生的数据训练模型。主流模型如下
补充策略
实时热点,关注最新动态
后续学习
学习深度学习相关的基础知识,实践排序层的模型。

Comments | NOTHING