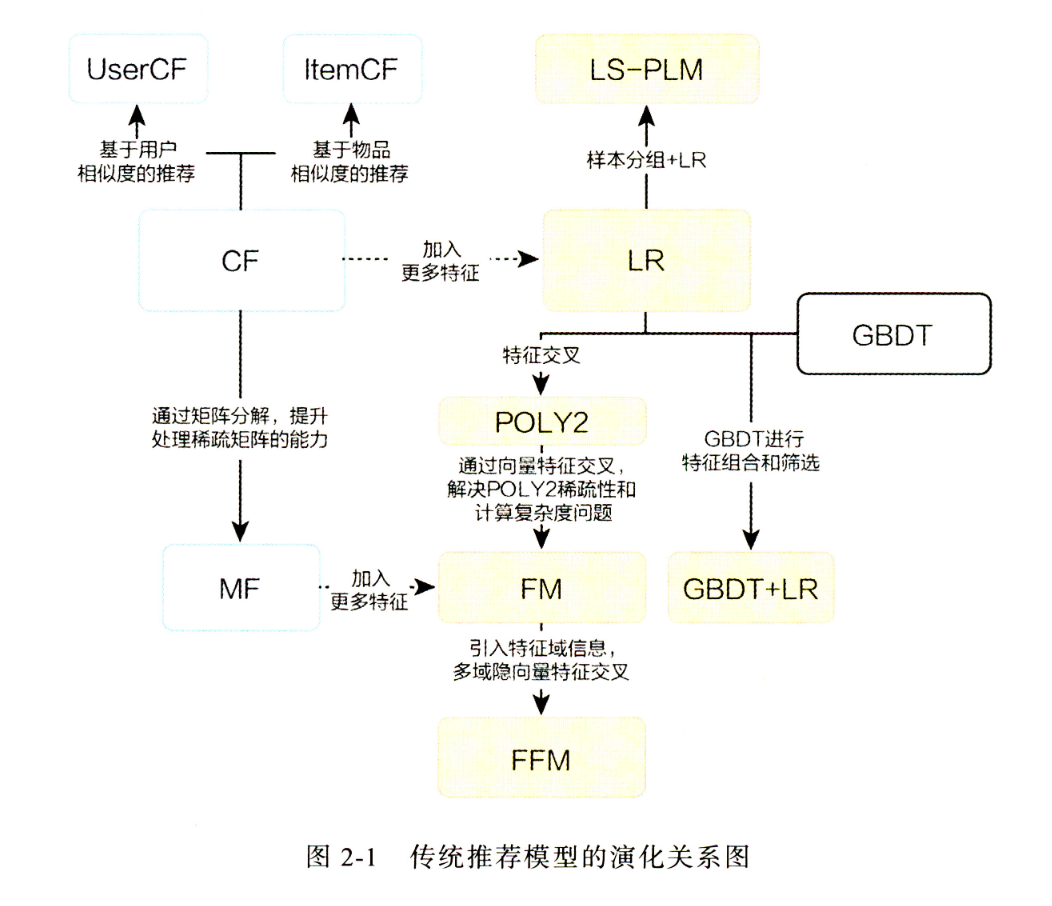
传统推荐模型演化关系图
协同过滤
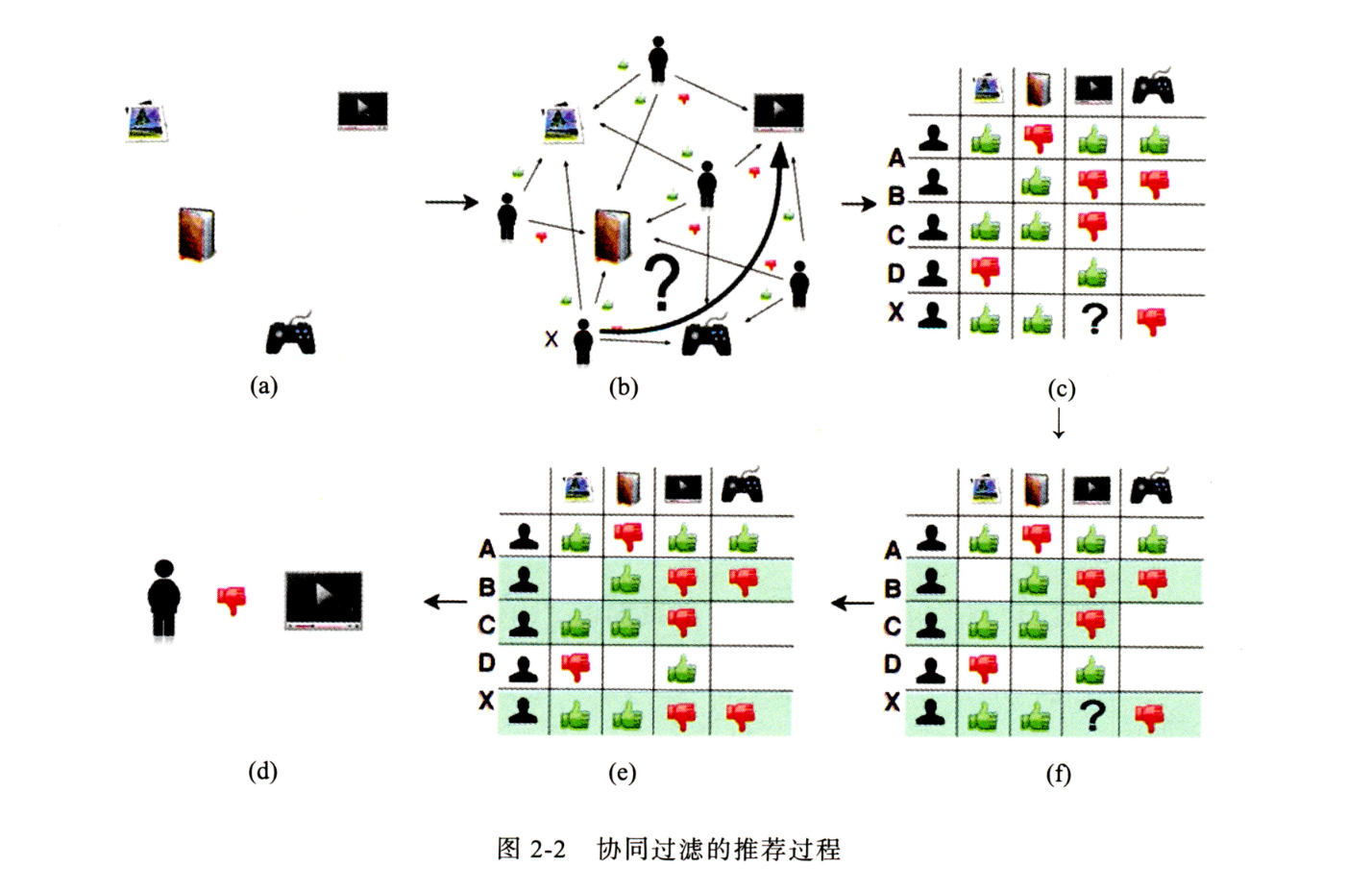
- 获取用户行为数据
- 用用户行为数据构建共现矩阵
- 计算用户之间的相似度(其实就是把对物品的评价作为了用户embedding)
- 根据相似用户进行对物品的评价进行加权运算后得到该用户对于物品评价的预测分
- 推荐高预测分物品
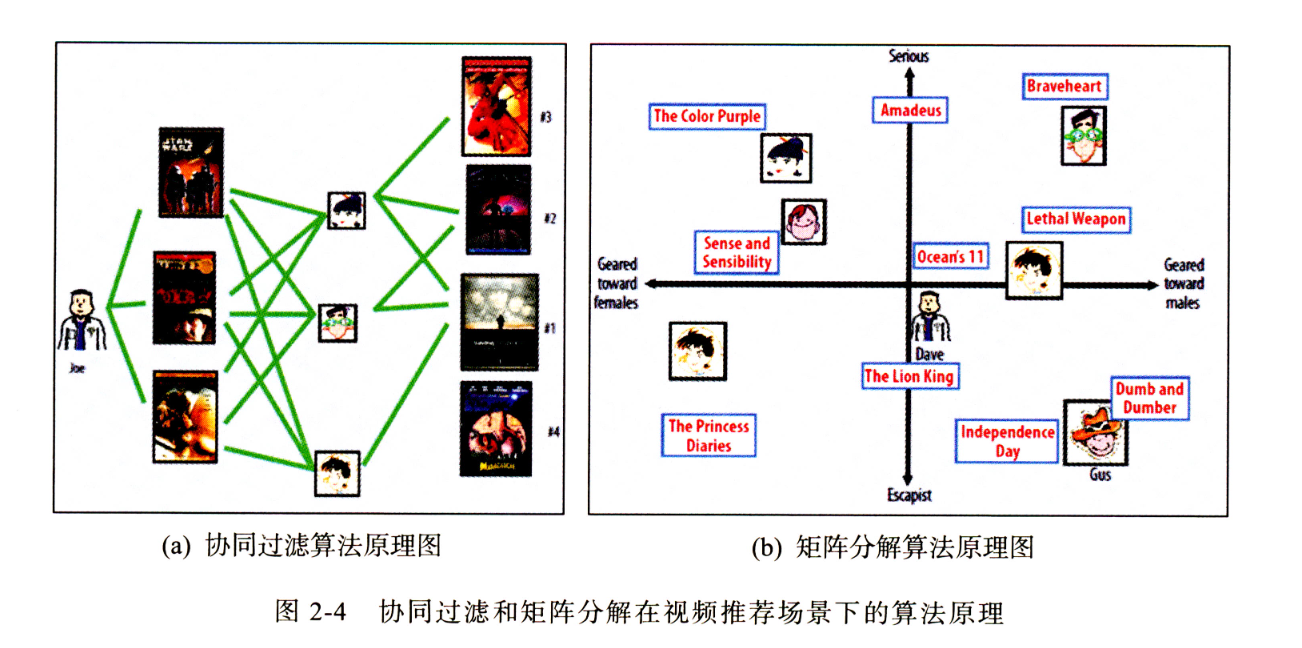
矩阵分解
矩阵分解是为了解决协同过滤的问题而产生的,协同过滤只根据共现矩阵来判断相似度,那么冷门的物品的行为更加的稀疏,缺少数据无法很好的判断相似性,就会导致头部效应(热门的物品被推荐的次数越来越多,冷门的越来越少),且只能由历史行为来判断相似性导致了对新物品的泛化能力不足。
- 获取用户行为数据
- 用用户行为数据构建共现矩阵
- 使用梯度下降将共现矩阵分解为物品特征矩阵与用户特征矩阵的乘积(隐向量)
- 根据隐向量之间的距离计算为用户找到最近的视频进行推荐
在矩阵分解时,所分解的隐向量的维度越大则该向量表达能力越强,泛化程度就越弱。
隐向量是稠密的,使用隐向量作为embedding可以衡量用户对于所有商品之间的相似度。
逻辑回归
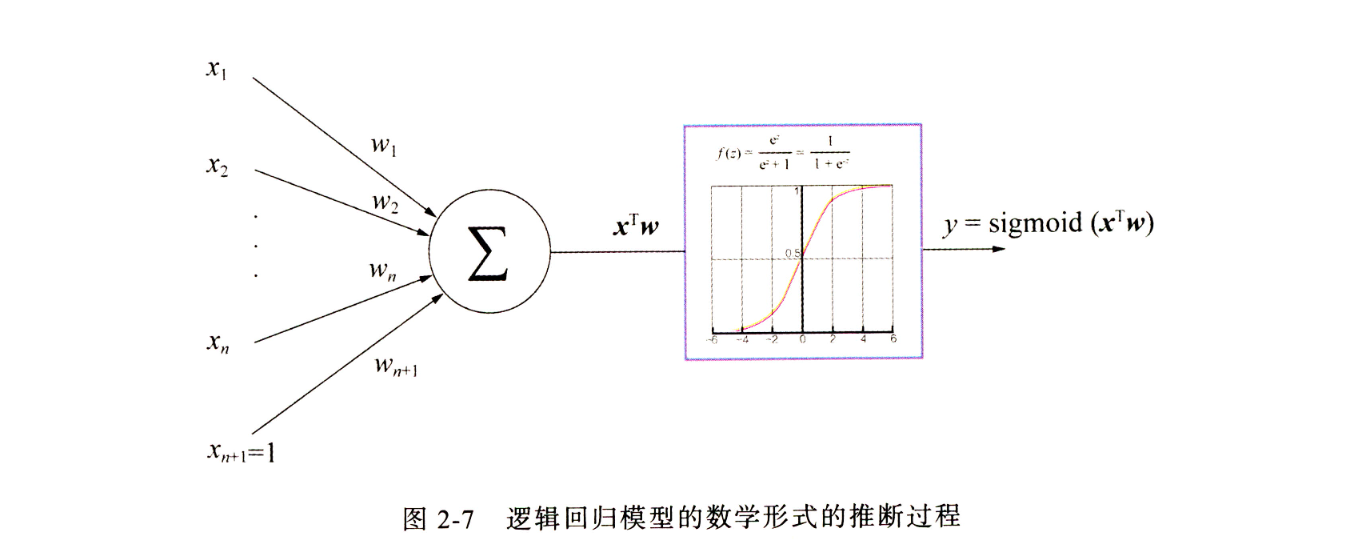
协同过滤与矩阵分解都只是基于用户行为产生的共现矩阵来进行计算,并没有融合用户或者物品的特征。逻辑回归通过组合特征,并且将推荐问题抽象成点击率预估来进行优化。
其实逻辑回归的模型表达就像深度学习中的单层感知机,输入是特征,线性组合后输入进sigmoid激活函数,得到0-1之间的输出,则是点击率,模型优化方法是梯度下降,损失函数是交叉熵损失函数。
- 将特征量化成数值
- 确定优化目标(点击率)
- 利用已有数据让模型进行学习拟合,固定模型参数
- 新数据输入,得到输出进行预测点击
逻辑回归的局限性是只是讲特征进行线性组合,而没有进行特征交叉,会造成一定的信息损失。
FM(Factorization Machine)到FFM
为了解决逻辑回归无法进行特征交叉的局限性,产生了POLY2模型。该模型对所有特征进行了两两交叉,并对所有的特征组合赋予权重。POLY2通过暴力组合特征的方式,在一定程度上解决了特征组合的问题。POLY2模型本质上仍是线性模型,其训练方法与逻辑回归并无区别,因此便于工程上的兼容。

POLY2的两两组合使模型的复杂度增加到了n的平方,且由于多数特征使用onehot表示,交叉后产生的特征更加的稀疏。
为了解决POLY2模型的缺陷,FM模型被提出。FM使用两个向量的内积取代了权重参数,FM模型中需要为每个特征学习到一个隐权重向量,在进行特征交叉时,使用两个权重向量内积作为权重。隐权重向量解决了特征稀疏的问题,降低了权重参数的数量。FM较于POLY2可能会丢失特定组合的记忆能力,相对的提升了泛化能力。
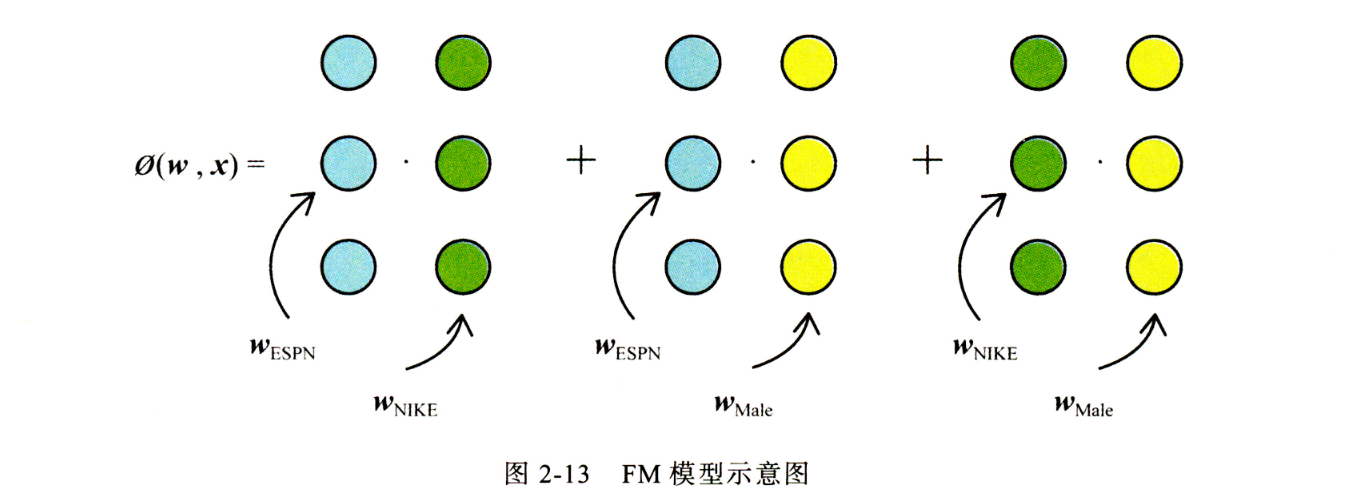
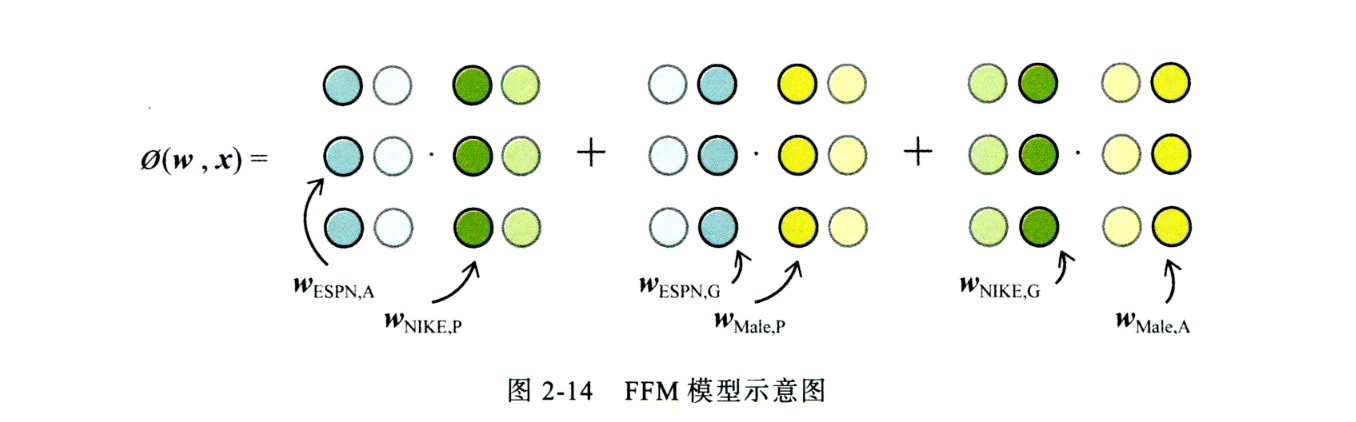
FFM对于FM的改进是使特征对应一组隐向量,达到与不同特征交叉时使用的隐向量可以不同,增加了模型的表达能力。
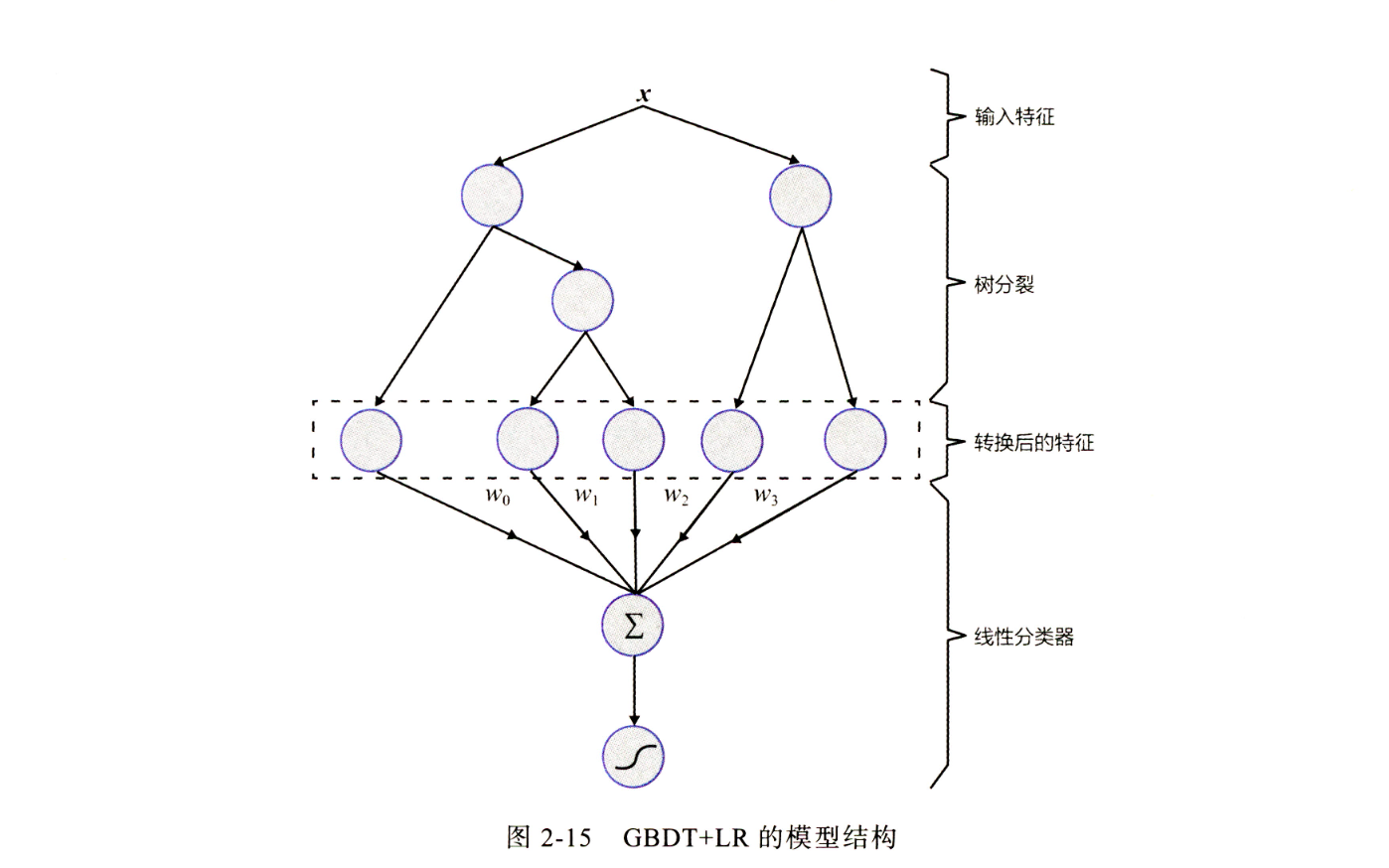
GBDT+LR
LS-PLM
LS-PLM,又被称为MLR(Mixed Logistic Regression,混合逻辑回归)模型。本质上,LS-PLM可以看作对逻辑回归的自然推广,它在逻辑回归的基础上采用分而治之的思路,先对样本进行分片,再在样本分片中应用逻辑回归进行CTR预估。
LS-PLM模型适用于工业级的推荐、广告等大规模稀疏数据的场景,主要是因为其具有以下两个优势。
- 端到端的非线性学习能力:LS-PLM具有样本分片的能力,因此能够挖掘出数据中蕴藏的非线性模式,省去了大量的人工样本处理和特征工程的过程,使LS-PLM算法可以端到端地完成训练,便于用一个全局模型对不同应用领域、业务场景进行统一建模。
- 模型的稀疏性强:LS-PLM在建模时引入了L1和L2,1范数,可以使最终训练出来的模型具有较高的稀疏度,使模型的部署更加轻量级。模型服务过程仅需使用权重非零特征,因此稀疏模型也使其在线推断的效率更高。
总结


Comments | NOTHING