摘要
学习用户行为背后复杂的特征交叉,对于最大化推荐系统的点击率至关重要。 尽管取得了很大的进展,但现有的方法似乎对低阶或高阶的交叉有很大的偏见,或者需要专业的特征工程。 在本文中,我们表明有可能推导出一个端到端的学习模型,同时强调低阶和高阶特征的相互作用。 我们所提出的模型DeepFM,在一个新的神经网络架构中结合了用于推荐的因子分解机和用于特征学习的深度学习的力量。 与谷歌最新的Wide & Deep模型相比,DeepFM的 "Wide "和 "Deep "部分的输入是共享的,除了原始特征之外不需要特征工程。 在基准数据和商业数据上,我们进行了全面的实验,以证明DeepFM在CTR预测方面比现有模型更有效和高效。
引言
预测点击率(CTR)在推荐系统中是至关重要的,其任务是估计用户点击一个推荐项目的概率。 在许多推荐系统中,目标是最大限度地提高点击率,因此返回给用户的项目应该根据估计的点击率进行排序;而在其他应用场景中,如在线广告,提高收入也很重要,因此可以将排名策略调整为所有候选项目的点击率,其中 "出价 "是系统在项目被用户点击时获得的收益。无论是哪种情况,很明显,关键在于正确估计CTR。
学习用户点击行为背后的隐性特征互动对预测点击率非常重要。 通过对主流应用市场的研究,我们发现人们经常在用餐时间下载送餐应用,这说明应用类别和时间戳之间的二阶交叉可以作为CTR的一个信号。第二个观察结果是,男性青少年喜欢射击游戏和RPG游戏,这意味着应用类别、用户类型和年龄的三阶交叉是CTR的另一个信号。总的来说,用户点击行为背后的这种特征交互可能是非常复杂的,其中低阶和高阶的特征交互都应该发挥重要作用。 根据google的Wide & Deep模型[Chenget al., 2016]的见解,同时考虑低阶和高阶特征的交互作用会比单独考虑任何一个特征的情况带来更多的改进。
关键的挑战是如何有效地对特征的相互作用进行建模。 有些特征的相互作用很容易理解,因此可以由专家来设计(如上面的例子)。然而,大多数其他特征的相互作用隐藏在数据中,很难事先识别(例如,经典的作为关联规则 "尿布和啤酒 "是从数据中挖掘出来的,而不是由专家发现的),这只能由机器学习自动捕捉。 即使是容易理解的互动,专家似乎也不可能对其进行详尽的建模,特别是当特征的数量很大时。
尽管它们很简单,但广义线性模型,如FTRL[McMahanet al., 2013],在实践中显示出不错的性能。 然而,线性模型缺乏学习特征相互作用的能力,常见的做法是在其特征向量中手动加入成对的特征交叉。 这样的方法很难普及到高阶特征交互的建模,或者那些从未或很少出现在训练数据中的特征交互[Rendle, 2010]。因子化机器(FM)[Rendle, 2010]将成对的特征交互建模为特征间潜在向量的内积,并得到非常良好的结果。 虽然原则上FM可以对高阶特征的相互作用进行建模,但在实践中,由于复杂性高,通常只考虑2阶特征的交叉。
作为一种学习特征表示的强大方法,深度神经网络有可能学习相当复杂的特征交互。 一些想法将CNN和RNN扩展到CTR预测[Liuet al., 2015; Zhangetal., 2014],但基于CNN的模型偏向于相邻特征之间的互动,而基于RNN的模型更适合于具有顺序依赖性的点击数据。[Zhanget al., 2016]研究特征表示并提出因子化分解机器支持的神经网络(FNN)。该模型在应用DNN之前对FM进行预训练,因此受到FM能力的限制。Quet al., 2016]研究了特征的相互作用,在嵌入层和全连接层之间引入了一个乘积层,并提出了基于乘积的神经网络(PNN)。如[Chenget al., 2016]所述,PNN和FNN与其他深度模型一样,几乎没有捕捉到低阶特征的相互作用,这对于CTR预测也是至关重要的。 为了对低阶和高阶特征的相互作用进行建模,[Chenget al., 2016]提出了一个有趣的混合网络结构(Wide & Deep),结合了一个线性("宽")模型和一个深度模型。 在这个模型中,"wide部分 "和 "deep部分 "分别需要两个不同的输入,而 "wide部分 "的输入仍然依赖于专业的特征工程。
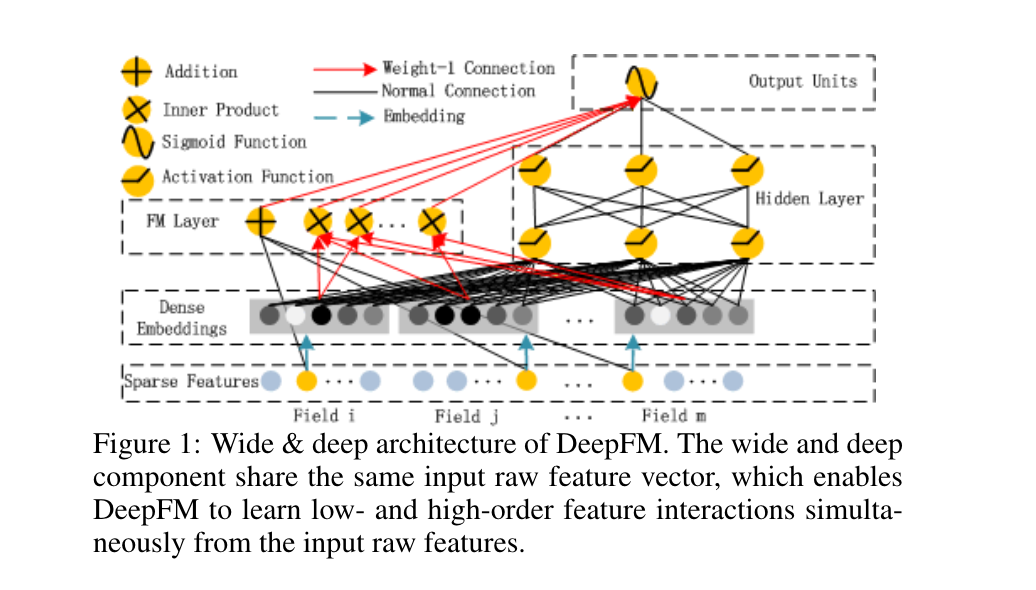
我们可以看到,现有的模型都偏向于低阶或高阶的特征交互,或者依赖于特征工程。 在本文中,我们表明有可能推导出一个学习模型,该模型能够以端到端的方式学习所有等级的特征交互,除了原始特征外,没有任何特征工程。我们的主要贡献总结如下:
- 我们提出了一个新的神经网络模型DeepFM(图1),它整合了FM和深度神经网络(DNN)的架构。它像FM一样对低阶特征的交互进行建模,像DNN一样对高阶特征的交互进行建模。 与wide & deep模型不同[Chenget al., 2016],DeepFM可以在没有任何特征工程的情况下进行端到端的训练。
- 与[Chenget al., 2016]不同的是,DeepFM可以有效地进行训练,因为其wide部分和deep部分共享相同的输入和embedding向量。在[Chengetal., 2016]中,输入向量可能是巨大的,因为它在其wide部分的输入向量中包含了手工设计的成对特征交互,这也大大增加了其复杂性
- 我们在基准数据和商业数据上对DeepFM进行了评估,结果显示在CTR预测方面比现有的模型有一致的改进。
我们的做法
假设训练的数据集由
DeepFM
我们的目标是学习低阶和高阶特征的相互作用。为此,我们提出了一个基于因子分解机的神经网络(DeepFM)。如图
FM模块
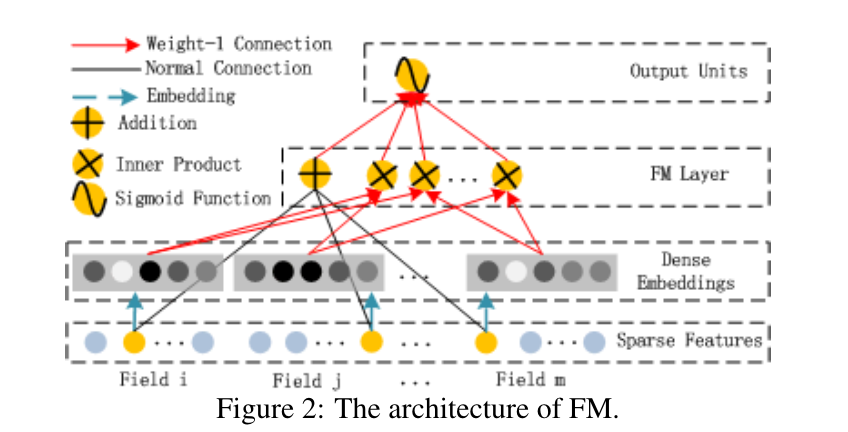
FM组件是一个因式分解机,在[Rendle, 2010]中被提出来学习用于推荐的特征相互作用。 除了特征间的线性(第1阶)相互作用外,FM将成对(第2阶)特征的相互作用建模为各自特征隐向量的内积。
它能比以前的方法更有效地捕捉第二阶特征的相互作用,特别是在数据集稀疏的情况下。 在以前的方法中,只有当特征
如图2所示,FM的输出是一个加法单元和若干内积单元的和:
Deep模块
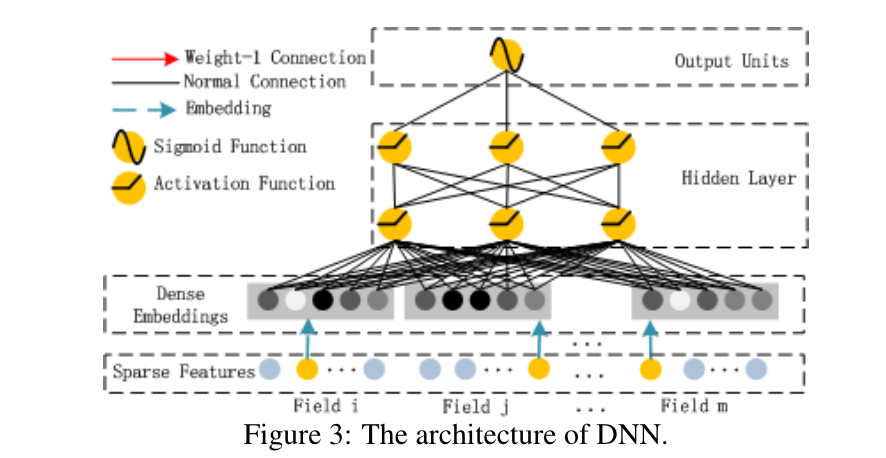
deep组件是一个前馈神经网络,用于学习高阶特征的相互作用。 如图3所示,一个数据记录(一个向量)被送入神经网络。 与以图像[Heet al., 2016]或音频[Boulanger-Lewandowskiet al., 2013]数据作为输入的神经网络相比,CTR预测的输入是非常不同的,这需要一个新的网络架构设计。 具体来说,CTR预测的原始特征输入向量通常是高度稀疏的,高维的,分类的,连续的,混合的,并按领域分组(如性别,地点,年龄)。 这就需要一个嵌入层,将输入向量压缩成低维、密集的实值向量,然后再进一步送入第一个隐藏层,否则网络的训练就会变得不堪重负。
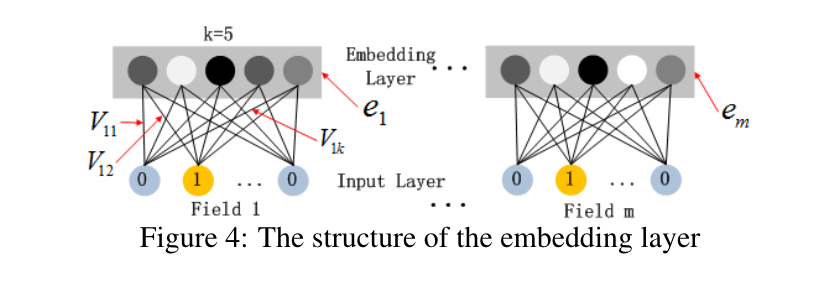
图4强调了从输入层到嵌入层的子网络结构。我们想指出这个网络结构的两个有趣的特点。1)虽然不同的输入领域向量的长度可以不同,但其输出嵌入的大小是相同的(
其中
其中
值得指出的是,FM组件和Deep组件共享相同的特征嵌入,这带来了两个重要的好处。1)它从原始特征中学习低阶和高阶的特征交互;2)不需要像Wide&Deep中要求的那样,对输入的特征进行精巧的设计[Chenget al., 2016]。
与其他神经网络的关系
受到深度学习在各种应用中的巨大成功的启发,近期一些用于CTR预测的深度模型被开发了出来。 本节将所提出的DeepFM与现有的CTR预测的深度模型进行比较。
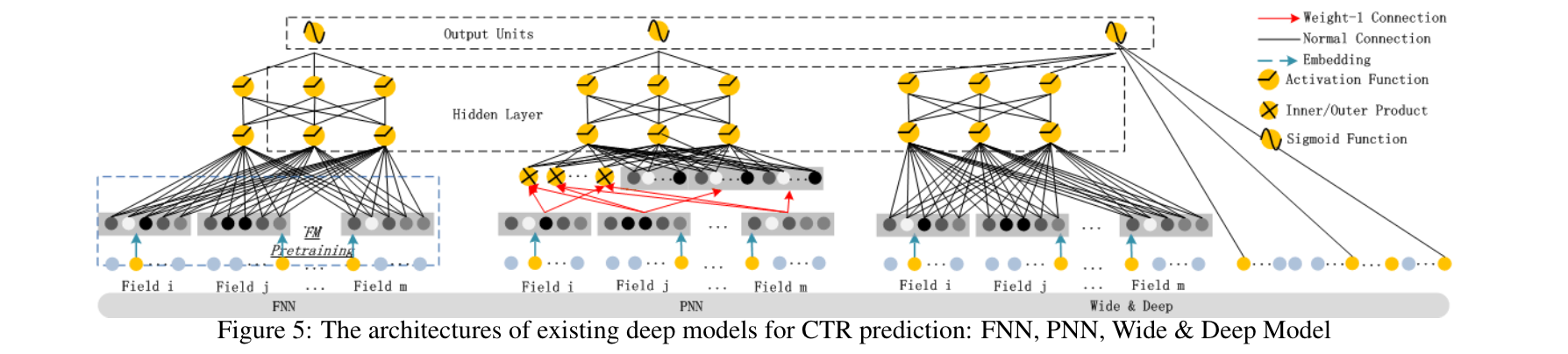
FNN
如图5(左)所示,FNN是一个FM初始化的前馈神经网络[Zhanget al., 2016]。FM预训练策略导致了两个限制。1)嵌入参数可能会受到FM的过度影响;2)效率因预训练阶段引入的开销而降低。此外,FNN只捕获高阶特征的相互作用。 相比之下,DeepFM不需要预训练,它可以同时学习高阶和低阶特征的相互作用。
PNN
为了捕捉高阶特征的相互作用,PNN在嵌入层和第一隐藏层之间设置了一个product层[Quet al., 2016]。 根据乘积操作的不同类型,有三种变体:IPNN、OPNN和PNN,其中IPNN是基于向量的内积,OPNN是基于外积,PNN是基于内积和外积。 与FNN一样,所有PNN都忽略了低阶特征的相互作用。
Wide & Deep
谷歌提出的 Wide & Deep模型(图5(右))是对低阶和高阶特征交互同时进行建模。如[Chenget al., 2016]中所展示的,在输入到 "Wide"的部分(例如,在应用推荐中用户安装的应用和浏览过的应用的交叉特征),需要有专业的特征工程。 相比之下,DeepFM不需要这样的专业知识来处理输入,而是直接从输入的原始特征中学习。
这个模型的一个直接的扩展是用FM代替LR(我们也在第3节中评估这个扩展)。 这种扩展与DeepFM相似,但DeepFM在FM和深度组件之间共享特征嵌入。 特征嵌入的共享策略通过低阶和高阶特征的相互作用影响(以反向传播的方式)特征表征,这使得表征的模型更加精确。
总结
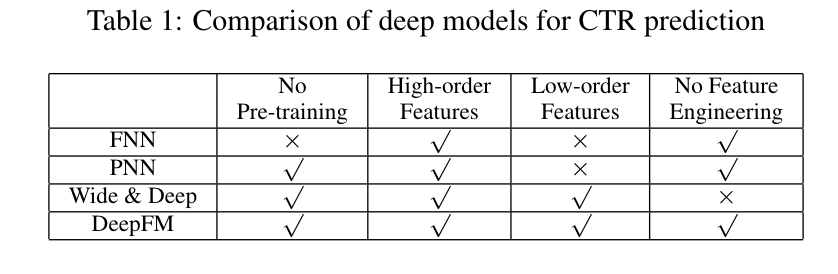
综上所述,表1列出了DeepFM与其他深度模型在四个方面的关系。可以看出,DeepFM是唯一一个不需要预训练、不需要特征工程的模型,并且可以捕获低阶和高阶特征的相互作用。
实验结果
在这一节中,我们将我们提出的DeepFM和其他最先进的模型进行了经验性的比较。 评估结果表明,我们提出的DeepFM比其他最先进的模型更有效,DeepFM的效率与所有深度模型中最好的模型相当。
实验步骤
数据集
我们在以下两个数据集上评估我们提出的DeepFM的有效性和效率
1)Criteo数据集:Criteo数据集5包括4500万用户的点击记录。 其中有13个连续的特征和26个类别的特征。 我们将该数据集分成两部分:90%用于训练,其余10%用于测试。
1)公司数据集:为了验证DeepFM在实际工业CTR预测中的表现,我们在公司数据集上进行了实验。 我们从公司应用商店的游戏中心收集连续7天的用户点击记录进行训练,接下来的1天进行测试。 在这个数据集中,有应用的特征(如标识、类别等),有用户的特征(如用户下载的应用等),还有上下文特征(如操作时间等)。
评价指标
我们在实验中使用了两个评价指标:AUC(ROC曲线下与坐标轴围成的面积)和Logloss(交叉熵)。
模型比对
我们在实验中比较了9个模型:LR、FM、FNN、PNN(三个变体)、Wide & Deep(两个变体)以及DeepFM。在Wide & Deep模型中,为了消除特征工程的努力,我们还对原来的Wide & Deep模型进行了调整,用FM代替LR作为Wide的部分。为了区分Wide & Deep的这两个变体,我们分别命名为LR & DNN和FM & DNN。
参数设置
为了评估Criteo数据集上的模型,我们遵循[Quet al., 2016]中对FNN和PNN的参数设置:(1)dropout:0.5;(2)网络结构: 400-400-400;(3)优化器:Adam;(4)激活函数:IPNN为tanh,其他深度模型为relu。 为了公平起见,我们提出的DeepFM使用了相同的设置。 LR和FM的优化器分别是FTRL和Adam,FM的隐向量维度是10。
为了使每个模型在公司数据集上达到最佳性能,我们进行了仔细的参数研究,这将在第3.3节讨论。
性能评估
效率比较
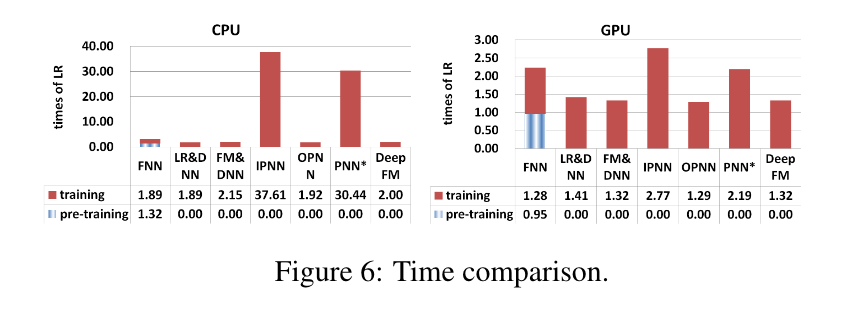
深度学习模型的效率对现实世界的应用非常重要。 我们通过以下公式比较不同模型在Criteo数据集上的效率:
结果显示在图6中,包括在CPU(左)和GPU(右)上的测试,我们观察到以下结果。 1)对FNN的预训练使其效率降低;2)虽然IPNN和PNN在GPU上的速度高于其他模型,但由于内积运算效率不高,它们的计算成本仍然很高;3)DeepFM在两个测试中几乎达到了最高效率
效果比较
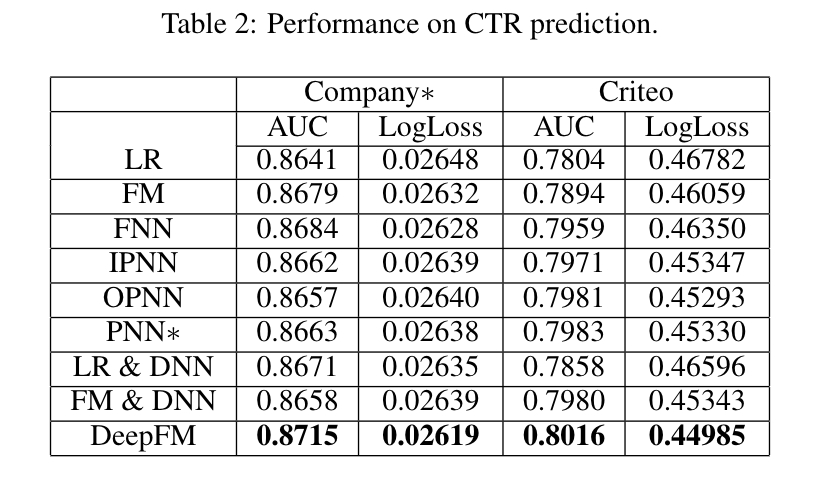
表2显示了不同模型在Criteo数据集和公司数据集上的CTR预测性能(注意,表中的数字是5次训练-测试的平均值,AUC和Logloss的方差在1E-5之间),我们有以下观察结果:
- 学习特征的相互作用可以提高CTR预测模型的性能。 这一观察结果来自于LR(它是唯一不考虑特征交互作用的模型)比其他模型的表现更差。 作为最好的模型,DeepFM在公司和Criteo数据集的AUC方面比LR高出0.82%和2.6%(在Logloss方面高出1.1%和4.0%)。
- 同时适当地学习高阶和低阶特征的相互作用,可以提高CTR预测模型的性能。 DeepFM优于只学习低阶特征交互(即FM)或高阶特征交互(即FNNN、IPNN、OPNN和PNN)的模型。 与第二好的模型相比,DeepFM在Company和Criteo数据集上取得了超过0.34%和0.41%的AUC(0.34%和0.76%的Logloss)。
- 同时学习高阶和低阶特征交互,同时共享高阶和低阶特征交互学习的特征嵌入,提高了CTR预测模型的性能。DeepFM优于使用单独特征嵌入学习高阶和低阶特征交互的模型(即LR & DNN和FM & DNN)。与这两个模型相比,DeepFM在Company和Criteo数据集上的AUC超过了0.48%和0.44%(Logloss为0.58%和0.80%)。
总的来说,我们提出的DeepFM模型在公司数据集上的AUC和Logloss分别比竞争对手多出0.34%和0.35%。 事实上,离线AUC评估的小幅改善可能会导致在线CTR的大幅增加。正如[Chengetal., 2016]中所报道的,与LR相比,Wide & Deep将AUC提高了0.275%(离线),在线CTR的提高是3.9%。 公司的应用商店每天的营业额是数百万美元,因此,即使CTR提高几个百分点,每年也会带来额外的数百万美元。 此外,我们还对我们提出的DeepFM和其他比较模型进行了t检验。 在公司的Logloss指标下,DeepFM对FM和DNN的p值小于
超参数学习
我们研究了不同深度模型的不同超参数,对公司数据集的影响。 顺序是:1)激活函数;2)dropout几率;3)每层的神经元数量;4)隐藏层的数量;5)网络形状
激活函数
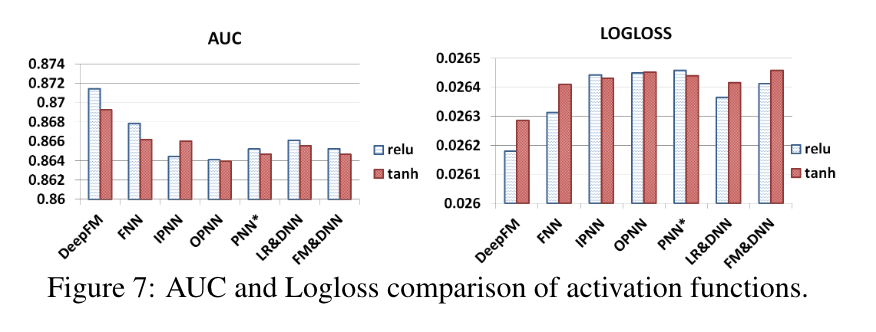
根据[Quet al., 2016],relu和tan比sigmoid更适用于深度模型。在本文中,我们比较了应用relu和tanh时深度模型的性能。如图7所示,对于所有的深度模型,relu比tanh更合适,除了IPNN。可能的原因是,relu诱导了稀疏性。
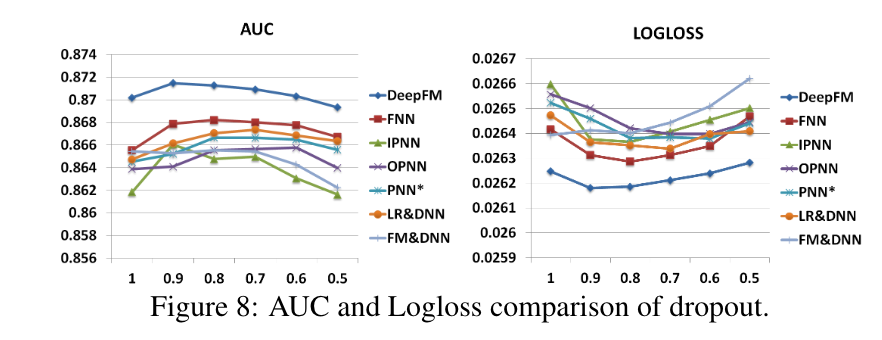
dropout
Dropout[Srivastavaet al., 2014]指的是一个神经元被保留在网络中的概率。 Dropout是一种正则化技术,用于折中神经网络的精度和复杂性。我们将Dropout设置为1.0、0.9、0.8、0.7、0.6和0.5。如图8所示,当dropout被适当设置时(从0.6到0.9),所有的模型都能达到自己的最佳性能。 该结果表明,在模型中加入合理的随机性可以加强模型的稳健性。
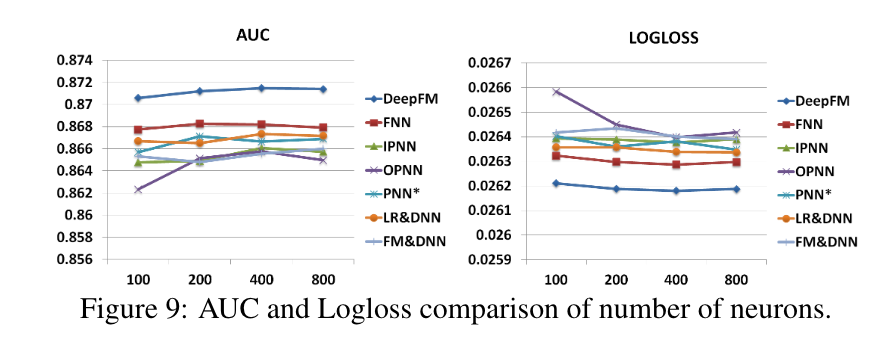
每层的神经元数量
当其他因素保持不变时,增加每层的神经元数量会带来复杂性。 从图9中我们可以看到,增加神经元的数量并不总是带来好处。例如,当每层的神经元数量从400个增加到800个时,DeepFM表现稳定;更糟糕的是,当我们将神经元数量从400个增加到800个时,OPN的表现更差。 这是因为一个过于复杂的模型很容易过度拟合。 在我们的数据集中,每层200或400个神经元是一个不错的选择。
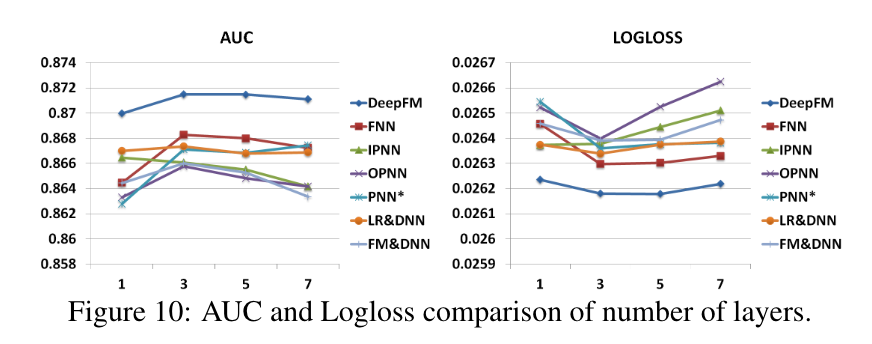
隐藏层的数量
如图10所示,增加隐藏层的数量在开始时提高了模型的性能,然而,如果隐藏层的数量不断增加,因为过度拟合它们的性能就会下降。
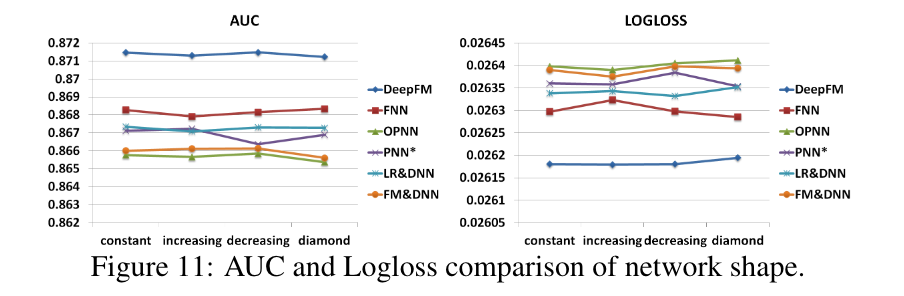
网络形状
我们测试了四种不同的网络形状:恒定、逐渐增加、逐渐减少和钻石型。 当我们改变网络形状时,我们固定隐藏层的数量和神经元的总数量。例如,当隐藏层数量为3,神经元总数为600时,那么四种不同的形状是:恒定(200-200-200),逐渐增加(100-200-300),逐渐减少(300-200-100),以及钻石型(150-300-150)。 从图11中我们可以看出,"恒定 "的网络形状在经验上优于其他三个选项,这与之前的研究一致[Larochelleet al., 2009]。
相关工作
本文提出了一个新的深度神经网络用于CTR预测。最相关的领域是CTR预测和推荐系统的深度学习。
CTR预测在推荐系统中起着重要作用[Richardsonet al., 2007; Juanet al., 2016]。 除了广义线性模型和FM,还有一些其他的模型被提出来用于CTR预测,如基于树的模型[Heetal., 2014],基于张量的模型[Rendle and Schmidt-Thieme,2010],支持向量机[Changet al., 2010],以及贝叶斯模型[Graepelet al.]
另一个相关领域是推荐系统中的深度学习。 在第1节和第2.2节中,已经提到了几个用于CTR预测的深度学习模型,因此我们在此不做讨论。 在CTR预测以外的推荐任务中也提出了一些深度学习模型(例如,[Covingtonet al., 2016; Salakhutdi-novet al., 2007; van den Oordet al., 2013; Wuet al.,2016; Zhenget al., 2016; Wuet al., 2017; Zhenget al.,2017])。[Salakhutdinovet al., 2007; Sedhainet al., 2015;Wanget al., 2015]提出通过深度学习改进协同过滤。[Wang and Wang, 2014;van den Oordet al., 2013]的作者通过深度学习提取内容特征来提高音乐推荐的性能。Chenet al., 2016]设计了一个深度学习网络来考虑图像特征和显示广告的基本特征。[Covingtonet al., 2016]为YouTube视频推荐开发了一个两阶段的深度学习框架。
结论
在本文中,我们提出了DeepFM,一个用于CTR预测的基于因子分解机的神经网络,以克服最先进模型的缺点。 DeepFM联合训练了一个Deep组件和一个FM组件。 它从这些优势中获得了性能的提高。 1)它不需要任何预训练;2)它同时学习高阶和低阶特征的相互作用;3)它引入了特征嵌入的共享策略以避免特征工程。 在两个真实世界的数据集上的实验表明:1)DeepFM在两个数据集上的AUC和Logloss方面都优于最先进的模型;2)DeepFM的效率与最先进的深度模型相当。
致谢
This research was supported in part by NSFC under GrantNo. 61572158, National Key Technology R&D Programof MOST China under Grant No. 2014BAL05B06, Shen-zhen Science and Technology Program under Grant No.JSGG20150512145714247 and JCYJ20160330163900579
引用

Comments | NOTHING