摘要
我们提出了一种新的多任务学习架构,它允许学习特定任务的特征级注意力。我们的设计,即多任务注意力网络(MTAN),由一个包含全局特征库的单一共享网络,以及每个任务的软注意力模块组成。 这些模块允许从全局特征中学习特定的任务特征,同时允许在不同的任务中共享特征。 该架构可以进行端到端的训练,可以建立在任何前馈神经网络的基础上,实施起来很简单,而且参数有效。 我们在各种数据集上评估了我们的方法,包括图像到图像的预测和图像分类任务。 我们表明,与现有的方法相比,我们的架构在多任务学习中是最先进的,而且对多任务损失函数中的各种加权方案也不太敏感。代码见https://github.com/lorenmt/mtan。
引言
卷积神经网络(CNN)在一系列计算机视觉任务中取得了巨大成功,包括图像分类[11]、语义分割[1]和风格转移[13]。 然而,这些网络通常被设计为只实现一个特定的任务。 对于现实世界应用中更完整的视觉系统来说,一个可以同时执行多个任务的网络远比建立一系列独立的网络(每个任务都使用单独的网络)更可取。 这不仅在内存和推理速度方面更有效,而且在数据方面也更有效,因为相关的任务可能共享信息丰富的视觉特征。
这种类型的学习被称为多任务学习(MTL)[20, 14, 6],在本文中,我们提出了一个基于特征级注意力掩码的MTL的新架构,它为共享互补特征增加了更大的灵活性。 与标准的单任务学习相比,要在训练多个任务的同时成功地学习一个共享的表征提出了两个关键挑战:
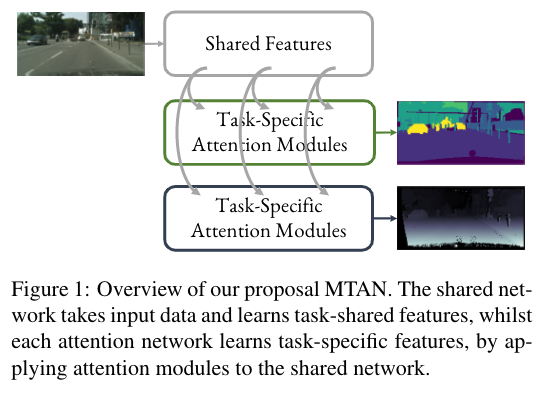
- 网络架构(如何共享): 一个多任务学习架构应该同时能表示任务共享的特征和特定任务的特征。通过这种方式,鼓励网络学习通用的表征(以避免过度拟合),同时也提供学习针对每个任务的特征的能力(以避免欠拟合)
- 损失函数(如何平衡任务): 一个多任务损失函数,对每个任务的相对贡献进行加权,应该使所有任务的学习具有同等的重要性,而不允许较容易的任务占主导地位。手动调整损失权重是繁琐的,最好是自动学习权重,或设计一个对不同权重具有鲁棒性的网络。
然而,大多数先前的MTL方法只关注这两个挑战中的一个,而对另一个保持标准的实现。在本文中,我们引入了一个统一的方法,通过设计一个新的网络来解决这两个挑战,该网络(i)能够自动学习任务共享和特定任务的特征,因此(ii)对损失加权的选择具有内在的稳健性。
我们提出的网络,我们称之为多任务注意力网络(MTAN)(见图1),由一个单一的共享网络组成,它学习了一个包含所有任务特征的全局特征池。 然后,对于每个任务,不是直接从共享特征库中学习,而是在共享网络的每个卷积块中应用一个软注意力掩码。 通过这种方式,每个注意力掩码自动确定共享特征对各自任务的重要性,允许以自我监督、端到端的方式学习任务共享特征和特定任务特征。 这种灵活性使我们能够学习更具表现力的特征组合,以便在不同的任务中进行归纳,同时仍然允许为每个单独的任务定制鉴别性的特征。 此外,自动选择哪些特征是共享的,哪些是特定任务的,允许一个高效的架构,其参数远远少于明确分离任务的多任务架构[26, 20] 。
根据任务的类型,MTAN可以建立在任何前馈神经网络上。 我们首先用SegNet[1]来评估MTAN,这是一个编码器-解码器网络,用于室外CityScapes数据集[4]的语义分割和深度估计任务,然后在更具挑战性的室内数据集NYUv2[21]上进行表面法线预测的额外任务。我们还在最近提出的视觉十项全能挑战赛[23]上,用不同的主干结构--Wide Residual网络[31]来测试我们的方法,解决10个单独的图像分类任务。 结果表明,MTAN的性能优于几个基线模型,在多任务学习方面具有竞争力,同时参数效率更高,因此随着任务数量的增加,扩展性更强。此外,与基线相比,我们的方法对损失函数中的加权方案的选择显示出更大的稳健性。 作为对这种稳健性评估的一部分,我们还提出了一种新的加权方案,即动态加权平均法(DWA),它通过考虑每个任务损失的变化率来适应任务加权的时间。
相关工作
多任务学习(MTL)一词已被广泛用于机器学习中[2, 8, 6, 17],与转移学习[22, 18]和持续学习[29]有相似之处。 在计算机视觉中,多任务学习已被用于学习类似的任务,如多领域的图像分类[23],姿势估计和动作识别[9],以及深度、表面法线和语义类的密集预测[20,7]。在本文中,我们考虑了多任务学习的两个重要方面:如何设计一个好的多任务网络结构,以及如何平衡多任务学习中所有任务的特征共享?
大多数用于计算机视觉的多任务学习网络架构是基于现有的CNN架构设计的。例如,交叉缝合网络[20]每个任务包含一个标准的前馈网络,交叉缝合单元允许特征在不同的任务中共享。 基于ResNet101架构[30]的自监督方法[6],从单个共享网络的不同层学习特征的规则化组合。 UberNet[16]提出了一种图像金字塔方法来处理多个分辨率的图像,对于每个分辨率,在共享的VGG-Net[27]的顶部形成额外的特定任务层。 渐进式网络[26]使用一连串逐步训练的网络在任务之间转移知识。 然而,交叉缝合网络和渐进网络等架构需要大量的网络参数,并随着任务数量的增加而线性扩展。 相比之下,我们的模型在每个学习任务中只需要增加10%的参数。
关于多任务学习中特征共享的平衡问题,在[20,14]中有大量的实验分析,这两篇论文都认为不同的共享量和权重对不同的任务来说是最有效的。 对任务进行适当加权的一个例子是使用权重不确定性[14],它利用任务的不确定性修改了多任务学习中的损失函数。另一种方法是GradNorm[3],它随着时间的推移操纵梯度规范来控制训练的动态性。作为使用任务损失来确定任务难度的替代方法,动态任务优先化[10]鼓励直接使用性能指标(如准确率和精确度)来确定困难任务的优先次序。
Multi-Task Attention Network
现在我们介绍一下我们新颖的多任务学习架构,多任务注意网络(MTAN)。虽然该架构可以被纳入任何前馈网络,但在下一节中,我们将演示如何将MTAN建立在一个编码器-解码器网络SegNet[1]上。这个例子的配置允许图像与图像之间密集的像素级预测,如语义分割、深度估计和表面法线预测。
架构设计
MTAN由两部分组成:一个单一的共享网络和K个特定任务的注意力网络。 共享网络可以根据特定的任务来设计,而每个特定任务的网络由一组注意力模块组成,它们与共享网络相连接。 每个注意力模块对共享网络的一个特定层应用软性注意力掩码,以学习特定任务的特征。因此,注意力掩码可以被视为共享网络的特征选择器,它以端到端的方式自动学习,而共享网络则在所有任务中学习一个紧凑密集的全局特征库。
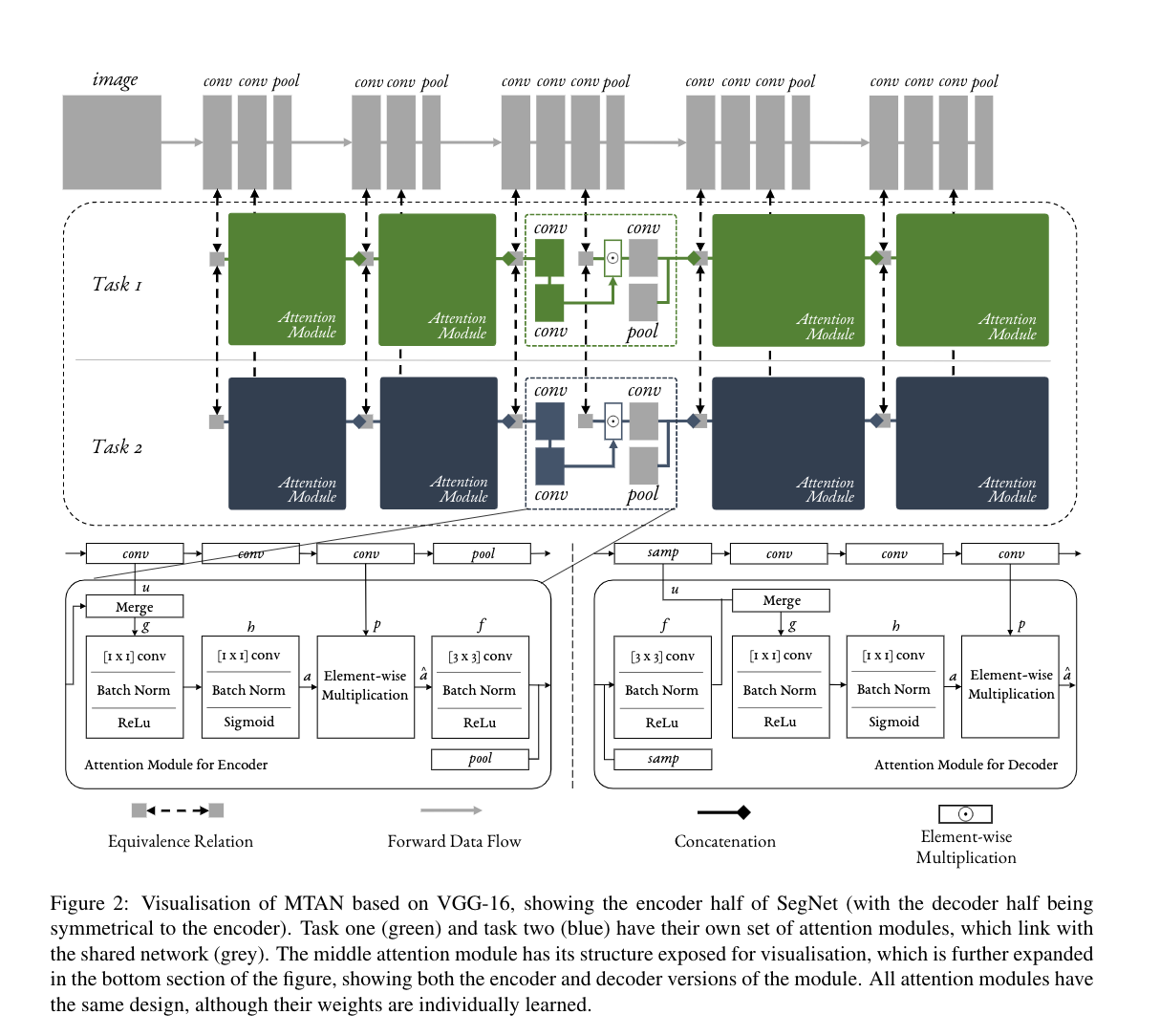
( 基于VGG-16的MTAN的可视化,显示了SegNet的编码器部分(解码器部分与编码器对称)。 任务一(绿色)和任务二(蓝色)有自己的一套注意模块,与共享网络(灰色)相连接。中间的注意力模块的结构被暴露出来,以便可视化,这在图的底部部分被进一步扩展,显示了该模块的编码器和解码器版本。所有的注意力模块都有相同的设计,尽管它们的权重是单独学习的。)
图2显示了我们基于VGG-16[27]的网络的详细可视化,说明了Seg-Net的编码器部分。SegNet的解码器部分则与VGG-16对称。如图所示,每个注意力模块学习一个软注意力掩码,它本身取决于相应层的共享网络中的特征。因此,共享网络中的特征和软注意力掩码可以共同学习,以最大限度地提高共享特征在多个任务中的通用性,同时最大限度地提高注意力掩码所带来的特定任务性能。
特定任务注意力模块
注意力模块的设计是为了让特定任务的网络学习与任务相关的特征,通过对共享网络中的特征应用软注意力掩码,每个任务每个特征通道有一个注意力掩码。 我们将共享网络
其中,
如图2所示,编码器中的第一个注意力模块只将共享网络中的特征作为输入。但对于块
这里,
注意力掩码,使用sigmoid作为激活函数确保
模型目标
在一般的多任务学习中,有
这是任务特定损失
对于图像到图像的预测任务,我们认为从输入数据
-
对于语义分割,我们对来自深度softmax分类器的每个预测类标签应用了一个像素级的交叉熵损失
-
对于深度估计,我们应用L1正则化来比较预测的深度和地面真实的深度。我们在NYUv2室内场景数据集中使用真实深度,在CityScapes室外场景数据集中使用反向深度作为标准,这可以更容易地表示无限距离的点,如天空。
-
对于表面法线(仅在NYUv2中可用),我们在每个归一化的像素上与地面实况地图进行元素级别的点乘。
对于图像分类任务,我们将每个数据集视为一个任务,每个数据集代表一个领域的每个分类任务。 我们对所有的分类任务都采用标准的交叉熵损失。
实验结果
在本节中,我们在两类任务中评估了我们提出的方法:在第4.1节中对图像到图像的回归任务进行一对多的预测,在第4.2节中对图像分类任务(Visual Decathlon Challenge)进行多对多的预测。
图像到图像的预测(一对多)
在本节中,我们对建立在SegNet[1]基础上的MTAN进行了图像间的预测任务评估。 我们首先在第4.1.1节中介绍了用于验证的数据集,并在第4.1.2节中介绍了几个用于比较的基线。 在第4.1.3节中,我们介绍了一种新的自适应加权方法,在第4.1.4节中,我们展示了MTAN与单任务和多任务基线方法相比,采用各种加权方法的有效性。 在第4.1.5节中,我们探讨了我们的方法的性能是如何随着任务的复杂性而变化的,在第4.1.6节中,我们展示了学到的注意力掩码的可视化。
数据集
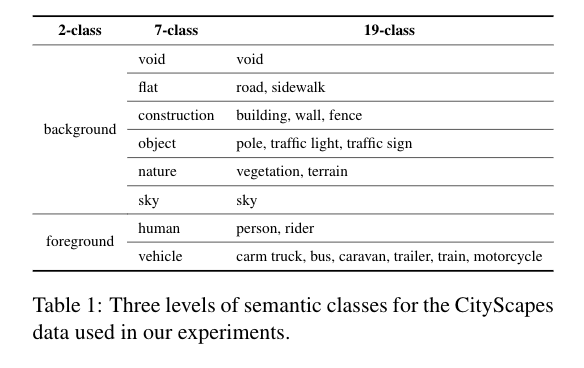
CityScapes CityScapes数据集[4]由高分辨率的街景图像组成。 我们将这个数据集用于两个任务:语义分割和深度估计。 为了加快训练速度,所有训练和验证图像都被调整为[128×256]。 该数据集包含19个用于像素化语义分割的类别,以及真实的反向深度标签。 我们将深度估计任务与使用2类、7类或19类(不包括7类和19类中的空白组)的三级语义分割配对。19类和较粗的7类的标签定义与原始CityScapes数据集相同。 然后我们进一步创建一个只有背景和前景物体的2类数据集。 这些分割类的细节见表1。 我们在第4.1.4节对7类CityScapes数据集进行多任务学习。我们在第4.1.5节中比较了2/7/19类的结果,并在第4节中对这些注意图进行了可视化。
NYUv2 NYUv2数据集[21]是由RGB-D格式室内场景图像组成。 我们评估了三个学习任务的表现。在[5]中定义的13类语义分割,由微软Kinect的深度摄像头记录的真实深度数据,以及[7]中提供的表面法线。 为了加快训练速度,所有的训练和评估图像都被调整为[288×384]分辨率。
与CityScapes相比,NYUv2包含室内场景的图像,这些图像要复杂得多,因为视点可以有很大的变化,存在着可变化的照明条件,而且每个物体类别的外观在纹理和形状上有很大的变化。 我们评估了不同数据集的性能,以及不同数量的任务,并进一步评估了不同类别的复杂性,以便全面了解我们提出的方法在各种情况下的表现和规模。
基线
大多数图像对图像的多任务学习架构是基于特定的前馈神经网络设计的,或者是在不同的网络架构上实现的,因此它们通常不能根据已发表的结果直接进行比较。我们的方法是通用的,可以应用于任何前馈神经网络,因此为了进行公平的比较,我们在SegNet[1]的基础上实现了5个不同的网络架构(2个单任务+3个多任务),我们将其作为基线。
- Single-Task, One Task:用于单任务学习的vanilla SegNet
- Single-Task, STAN:单任务注意网络,我们直接应用我们提出的MTAN,同时只执行一项任务。
- Multi-Task, Split (Wide, Deep):标准的多任务学习,在最后一层拆分,为每个具体任务进行最终预测。 我们引入了Split的两个版本:Wide,我们调整了卷积过滤器的数量;Deep,我们调整了卷积层的数量,直到Split至少有MTAN一样多的参数。
- Multi-Task, Dense:一个共享网络与特定任务的网络一起,每个特定任务的网络从共享网络接收所有特征,没有任何注意力模块。
- Multi-Task, Cross-Stitch:Cross-Stitch网络[20],一个先前提出的自适应多任务学习方法,我们在SegNet上实现了这一方法。
请注意,所有的基线都被设计成至少比我们提出的MTAN有更多的参数,并被测试以验证我们提出的方法更好的性能是由于注意力模块,而不是简单地由于网络参数的增加。
动态加权平均数
对于大多数多任务学习网络来说,如果不能在这些任务之间找到正确的平衡,训练多个任务是很困难的,最近的方法已经试图解决这个问题[3, 14]。 为了在一系列的加权方案中测试我们的方法,我们提出了一个简单而有效的自适应加权方法,名为动态加权平均(DWA)。受GradNorm[3]的启发,该方法通过考虑每个任务的损失变化率来学习随时间变化的平均任务加权。但是,GradNorm需要访问网络的内部梯度,而我们的DWA建议只需要任务损失的数值,因此它的实现要简单得多。
通过DWA,我们将任务
这里,
在我们的实现中,损失值
图像到图像的预测结果
我们现在评估我们提出的MTAN方法在图像对图像多任务学习中的表现,基于SegNet架构。 我们使用7类的CityScapes数据集和13类的NYUv2数据集,比较了第4.1.2节中介绍的所有基线。
Training 对于每个网络架构,我们用三种加权方法进行了实验:平等加权、加权不确定性[14]和我们提出的DWA(用超参数温度T=2,根据经验发现在所有架构中是最佳的)。 我们没有包括GradNorm[3],因为它需要根据所有基线的特殊架构,手动选择子集网络权重,这分散了对架构本身的公平评估。我们用ADAM优化器[15]训练所有的模型,学习率为
Results 表2和表3显示了CityScales和NYUv2数据集在所有架构和所有损失函数加权方案中的实验结果。 结果还显示了每个架构的网络参数的数量。 我们的MTAN方法在CityScapes数据集中的表现与我们的基线Dense相似,而参数数量却不到一半,并且超过了所有其他基线。 对于更具挑战性的NYUv2数据集,我们的方法在所有加权方法和所有学习任务中都优于所有基线。
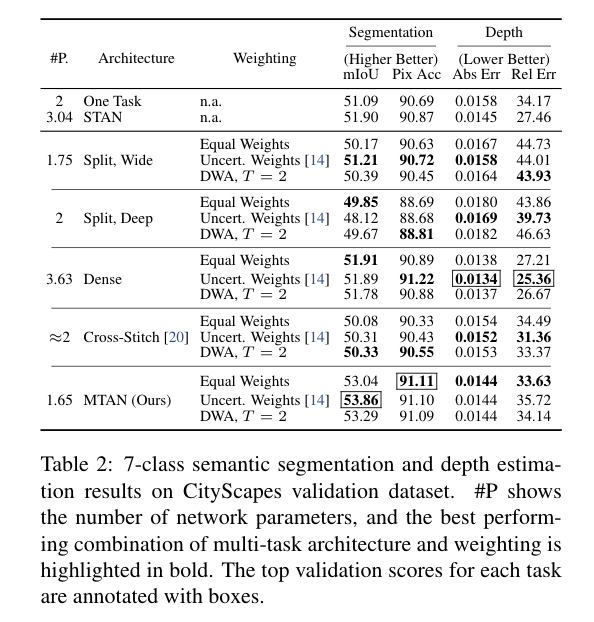
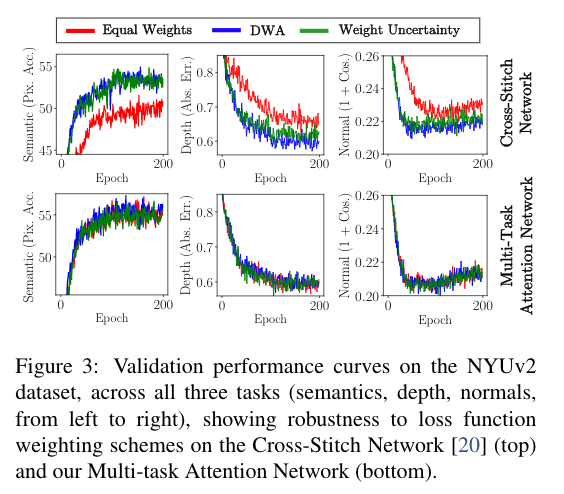
特别是,我们的方法有两个关键优势。 首先,由于有一个单一的共享特征池,并注意面具自动学习哪些特征需要共享,我们的方法在不需要额外的参数(列#P)的情况下,甚至在某些情况下参数明显较少的情况下,就能胜过其他方法。
其次,我们的方法在不同的损失函数加权方案中都能保持高性能,而且对加权方案的选择比其他方法更健壮,避免了对损失加权的繁琐调整。 我们通过与十字绣网络[20]的比较来说明我们的方法对加权方案的鲁棒性,在图3中绘制了关于NYUv2数据集中三个学习任务性能的学习曲线。 我们可以清楚地看到,我们的网络在不同的加权方案中遵循相似的学习趋势,相比之下,十字绣网络在不同的方案中产生明显不同的行为。
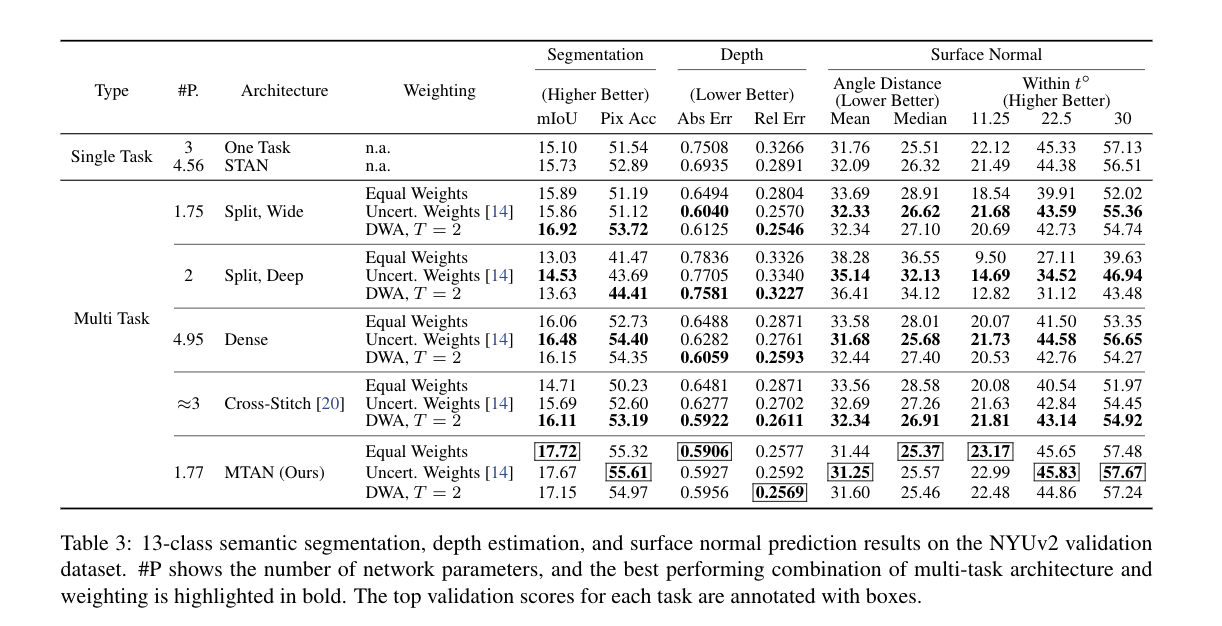
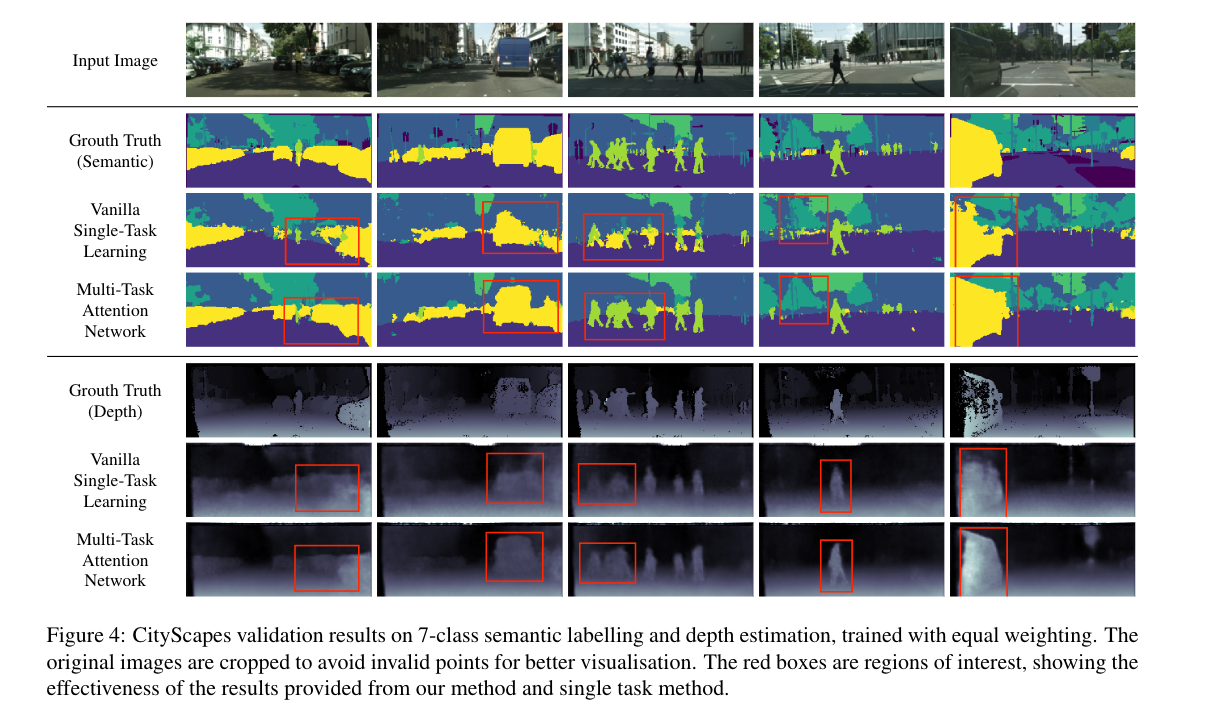
图4显示了城市景观验证数据集的定性结果。 我们可以看到我们的多任务学习方法比vanilla的单任务学习方法更有优势,物体的边缘明显更明显。
任务复杂性的影响
为了进一步检验多任务学习的好处,我们在City Scapes上评估了我们在不同数量的语义类别上的实现,所有实验中的深度标签是相同的。 我们用第4.1.4节中的相同设置来训练网络工程,并增加了一个多任务基线Split(标准版本),我们发现它比其他修改过的版本表现更好。所有的网络都以相同的权重进行训练。
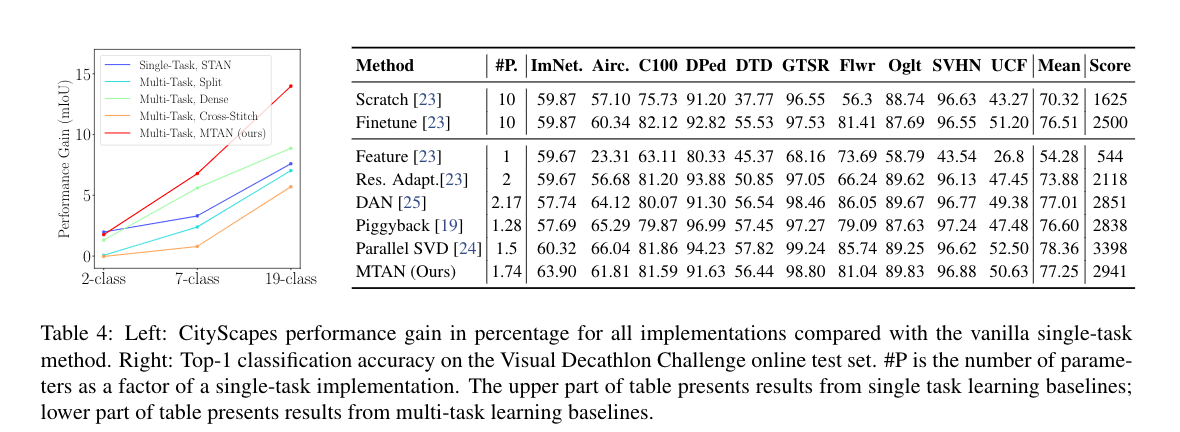
表4(左)显示了所有多任务实现和单任务STAN实现的验证性能改进,相对于城市景观数据集上的普通单任务学习的性能而言。 有趣的是,仅就2类设置而言,单任务注意力网络(STAN)比所有多任务方法表现得更好,因为它能够以简单的方式充分利用网络参数来完成简单的任务。 然而,对于更高的任务复杂性,多任务方法鼓励共享特征以更有效地利用可用的网络参数,然后导致更好的结果。我们还观察到,虽然所有的实现方法的相对性能增益随着任务复杂度的增加而增加,但我们的MTAN方法以更大的速度增加。
作为特征选择器的注意力掩码

为了理解所提出的注意力模块的作用,在图5中,我们将基于CityScapes数据集,对我们的网络学习的第一层注意力掩码进行可视化。 我们可以看到两个任务之间的注意力掩码有明显的区别,每个掩码都作为一个特征选择器来屏蔽掉共享特征中不具参考价值的部分,而专注于对每个任务有用的部分。 值得注意的是,深度预测掩码比语义掩码的对比度要高得多,这表明虽然所有的共享特征一般都对语义任务有用,但深度任务更受益于对任务特定特征的提取。
视觉十项全能挑战(多对多)
最后,我们在最近推出的视觉十项全能挑战赛上评估了我们的方法,该挑战赛包括10个单独的图像分类任务(多对多的预测)。 对这项挑战的评估报告了每个任务的准确度,并根据这些准确度分配了一个最高值为10,000(每个任务1,000)的累积分数。关于挑战设置、评估和使用的数据集的完整细节,可以在http://www.robots.ox.ac.uk/~vgg/decathlon/找到。
表4(右)显示了挑战赛的在线测试集的结果。 与之前的工作一致,我们在每个区块的第一个卷积层中应用了基于Wide Residual Network[31]的MTAN,深度为28,拓宽系数为4,跨度为2。 我们使用100个批次的规模来训练我们的模型,SGD的学习率为0.1,所有10个分类任务的权重衰减为
结论
在这项工作中,我们提出了一种新的多任务学习方法,即多任务注意网络(MTAN)。该网络结构包括一个全局特征库,以及每个任务的特定注意力模块,它允许以端到端的方式自动学习任务共享的特征和特定的任务。 在NYUv2和CityScapes数据集上的多个密集预测任务,以及在视觉十项全能挑战赛上的多个图像分类任务的实验表明,我们的方法优于其他方法或具有竞争力,同时还显示出对损失函数中使用的特定任务加权方案的稳健性。 由于我们的方法能够通过注意力掩码共享权重,我们的方法在实现这一最先进的性能的同时,还具有高度的参数效率。
引用
[1] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla.Segnet: A deep convolutional encoder-decoder architecturefor image segmentation.IEEE transactions on pattern anal-ysis and machine intelligence, 39(12):2481–2495, 2017.
[2] Rich Caruana. Multitask learning. InLearning to learn,pages 95–133. Springer, 1998.
[3] Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and An-drew Rabinovich. Gradnorm: Gradient normalization foradaptive loss balancing in deep multitask networks. InInter-national Conference on Machine Learning, pages 793–802,2018.
[4] Marius Cordts, Mohamed Omran, Sebastian Ramos, TimoRehfeld, Markus Enzweiler, Rodrigo Benenson, UweFranke, Stefan Roth, and Bernt Schiele.The cityscapesdataset for semantic urban scene understanding. InProceed-ings of the IEEE Conference on Computer Vision and PatternRecognition, pages 3213–3223, 2016.
[5] Camille Couprie, Cl ́ement Farabet, Laurent Najman, andYann Lecun. Indoor semantic segmentation using depth in-formation. InInternational Conference on Learning Repre-sentations (ICLR2013), April 2013, 2013.
[6] Carl Doersch and Andrew Zisserman.Multi-task self-supervised visual learning. InThe IEEE International Con-ference on Computer Vision (ICCV), Oct 2017.
[7] David Eigen and Rob Fergus. Predicting depth, surface nor-mals and semantic labels with a common multi-scale con-volutional architecture. InProceedings of the IEEE Inter-national Conference on Computer Vision, pages 2650–2658,2015.
[8] Theodoros Evgeniou and Massimiliano Pontil.Regular-ized multi–task learning. InProceedings of the tenth ACMSIGKDD international conference on Knowledge discoveryand data mining, pages 109–117. ACM, 2004.
[9] Georgia Gkioxari, Bharath Hariharan, Ross Girshick, and Ji-tendra Malik. R-cnns for pose estimation and action detec-tion.arXiv preprint arXiv:1406.5212, 2014.
[10] Michelle Guo, Albert Haque, De-An Huang, Serena Ye-ung, and Li Fei-Fei. Dynamic task prioritization for multi-task learning. InEuropean Conference on Computer Vision,pages 282–299. Springer, 2018.
[11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. InProceed-ings of the IEEE conference on computer vision and patternrecognition, pages 770–778, 2016.
[12] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean.Distill-ing the knowledge in a neural network.arXiv preprintarXiv:1503.02531, 2015.
[13] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptuallosses for real-time style transfer and super-resolution. InEuropean Conference on Computer Vision, pages 694–711.Springer, 2016.
[14] Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-tasklearning using uncertainty to weigh losses for scene geome-try and semantics. InProceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition, pages 7482–7491, 2018.
[15] Diederik P Kingma and Jimmy Ba. Adam: A method forstochastic optimization.arXiv preprint arXiv:1412.6980,2014.
[16] Iasonas Kokkinos. Ubernet: Training a universal convolu-tional neural network for low-, mid-, and high-level visionusing diverse datasets and limited memory. InThe IEEEConference on Computer Vision and Pattern Recognition(CVPR), July 2017.
[17] Abhishek Kumar and Hal Daum ́e III. Learning task groupingand overlap in multi-task learning. InProceedings of the29th International Coference on International Conference onMachine Learning, pages 1723–1730. Omnipress, 2012.
[18] Mingsheng Long, Jianmin Wang, Guiguang Ding, JiaguangSun, and Philip S Yu. Transfer feature learning with jointdistribution adaptation. InProceedings of the IEEE inter-national conference on computer vision, pages 2200–2207,2013.
[19] Arun Mallya, Dillon Davis, and Svetlana Lazebnik. Piggy-back: Adapting a single network to multiple tasks by learn-ing to mask weights. InProceedings of the European Con-ference on Computer Vision (ECCV), pages 67–82, 2018.
[20] Ishan Misra, Abhinav Shrivastava, Abhinav Gupta, and Mar-tial Hebert. Cross-stitch networks for multi-task learning.InProceedings of the IEEE Conference on Computer Visionand Pattern Recognition, pages 3994–4003, 2016.
[21] Pushmeet Kohli Nathan Silberman, Derek Hoiem and RobFergus. Indoor segmentation and support inference fromrgbd images. InECCV, 2012.
[22] Sinno Jialin Pan and Qiang Yang. A survey on transfer learn-ing.IEEE Transactions on knowledge and data engineering,22(10):1345–1359, 2010.
[23] Sylvestre-Alvise Rebuffi, Hakan Bilen, and Andrea Vedaldi.Learning multiple visual domains with residual adapters. InAdvances in Neural Information Processing Systems, pages506–516, 2017.
[24] Sylvestre-Alvise Rebuffi, Hakan Bilen, and Andrea Vedaldi.Efficient parametrization of multi-domain deep neural net-works. InProceedings of the IEEE Conference on ComputerVision and Pattern Recognition, pages 8119–8127, 2018.
[25] Amir Rosenfeld and John K Tsotsos. Incremental learningthrough deep adaptation.IEEE transactions on pattern anal-ysis and machine intelligence, 2018.
[26] Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins,Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Raz-van Pascanu, and Raia Hadsell. Progressive neural networks.arXiv preprint arXiv:1606.04671, 2016.
[27] Karen Simonyan and Andrew Zisserman. Very deep convo-lutional networks for large-scale image recognition.arXivpreprint arXiv:1409.1556, 2014.
[28] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, IlyaSutskever, and Ruslan Salakhutdinov. Dropout: a simple wayto prevent neural networks from overfitting.The Journal ofMachine Learning Research, 15(1):1929–1958, 2014.
[29] Sebastian Thrun and Lorien Pratt.Learning to learn.Springer Science & Business Media, 2012.
[30] Fei Wang, Mengqing Jiang, Chen Qian, Shuo Yang, ChengLi, Honggang Zhang, Xiaogang Wang, and Xiaoou Tang.

Comments | NOTHING