摘要
近年来,基于神经结构的推荐系统已经取得了巨大的成功。然而,在处理高度稀疏的数据时,它们仍然没有达到预期的效果。自监督学习(SSL),作为一种新兴的利用无标签数据进行学习的技术,最近在许多领域引起了极大的关注。也有越来越多的研究着手于将SSL应用于推荐,以缓解数据稀少的问题。在这项调查中,我们对自监督推荐(SSR)的研究工作进行了及时和系统的回顾。具体来说,我们提出了SSR的排他性定义
,在此基础上,我们建立了一个全面的分类法,将现有的SSR方法分为四类:对比型、生成型、预测型和混合型。对于每一类,我们都沿着其概念和表述、所涉及的方法以及其优点和缺点展开叙述。同时,为了促进SSR模型的开发和评估,我们发布了一个开源库SELFRec,它包含了多个基准数据集和评估指标,并实现了一些最先进的SSR模型进行经验比较。最后,我们阐明了当前研究的局限性,并概述了未来的研究方向。
引言
作为能够发现用户潜在兴趣并简化决策方式的工具,推荐系统[1]已被广泛部署在各种在线电子商务平台上,以创造愉快的用户体验,同时推动收入的增加。近年来,在高表现力的深度神经结构的支持下,现代推荐系统[2], [3], [4]已经取得了巨大的成功并产生了巨大的收益。然而,深度推荐模型对数据的要求非常高。为了利用深度结构的优势,需要大量的训练数据。与可以通过众包进行的图像注解不同,推荐系统的数据获取成本很高,因为个性化的推荐依赖于用户自己产生的数据,而大多数用户通常只能消费/点击无数项目中的一小部分[5]。因此,数据稀疏的问题使深度推荐模型无法发挥其全部潜力[6]。
自监督学习(SSL)[7],作为一种新兴的学习范式,可以减少对人工标签的依赖,并能在大量无标签的数据上进行训练,最近受到了相当的关注。SSL的基本思想是通过精心设计的代理任务(即自监督任务),从丰富的无标签数据中提取信息和可转移的知识,其中的监督信号是半自动生成的。由于能够克服普遍存在的标签不足问题,SSL已被应用于广泛的领域,包括视觉表示学习[8],[9],[10],语言模型预训练[11],[12],音频表示学习[13],节点/图分类[14],[15]等,并且它已被证明是一种强大的技术。由于SSL的原理与推荐系统对更多注释数据的需求非常吻合,在SSL在上述领域的巨大成功的激励下,大量且不断增长的研究正朝着将SSL应用于推荐的方向前进。
自监督推荐(SSR)的早期原型可以追溯到无监督的方法,如基于自动编码器的推荐模型[16], [17],它依赖于不同的损坏数据来重建原始输入以避免过拟合。之后,SSR出现了基于网络嵌入的推荐模型[18], [19],其中随机行走的接近度被用作自我监督信号来捕捉用户和物品之间的相似性。在同一时期,一些基于生成对抗网络[20](GANs)的推荐模型[21], [22],增强了用户与物品的互动,可以看作是SSR的另一个体现。在2018年预训练的语言模型BERT[12]取得巨大突破后,SSL作为一个独立的概念,进入了人们的视线。随后,推荐社区开始接受SSL,随后的研究[23],[24],[25]将注意力转移到用类似完形填空的任务对顺序数据进行预训练的推荐模型。自2020年以来,SSL迎来了一个繁荣期,最新的基于SSL的方法在许多CV和NLP任务中的表现几乎与有监督的对等方法相当[9], [26]。特别是,对比学习(CL)[27]的重新出现极大地推动了SSL的发展。同时,人们也看到了对SSR的热情高涨[28]、[29]、[30]、[31]、[32]、[33]。SSR的范式变得多种多样,其应用场景也不再局限于顺序推荐。
尽管在CV、NLP[34]、[7]和图学习[35]、[36]、[37]等领域已经有一些关于SSL的调查,但尽管论文数量快速增长,SSR的研究工作还没有被系统地调查。
与上述领域不同的是,推荐涉及到大量的场景,这些场景的优化目标不同,并且处理多种类型的数据,因此很难将为CV、NLP和图任务设计的现成的SSL方法完美地推广到推荐中。因此,它为新型的SSL提供了土壤。同时,像高度倾斜的数据分布[38]、广泛服从的偏差[39]和大字典的分类特征[40]这些推荐系统特有的问题,也刺激了一系列独特的SSR方法,可以丰富SSL家族。随着SSR的日益盛行,我们迫切需要一个及时、系统的调查,以总结现有SSR研究工作的成果,讨论其优势和不足,从而促进未来的研究。为此,我们提出了一个最新的和全面的关于SSR前沿的回顾。总的来说,我们的贡献有四个方面:
- 我们调查了广泛的SSR方法,以涵盖尽可能多的相关论文。据我们所知,这是第一个专注于这个新课题的调查。
- 我们提供了SSR的排他性定义,并澄清了它与相关概念的联系。在此基础上,我们提出了一个全面的分类法,将现有的SSR方法分为四类:对比型、生成型、预测型和混合型。对于每一个类别,我们都沿着其概念和表述、所涉及的方法以及其优点和缺点展开叙述。我们相信这个定义和分类法为开发和定制新的SSR方法提供了一个清晰的设计空间。
- 我们发布了一个开源的库,以促进SSR模型的实施和评估。它包含了多个基准数据集和评价指标,并实现了10多个最先进的SSR方法进行经验比较。
- 我们阐明了现有研究的局限性,并确定了推进SSR的剩余挑战和未来方向。
论文收集。在这项调查中,我们回顾了60多篇纯粹专注于SSR的论文,并且是在2018年之后发布的。至于SSR的早期实现,如基于自动编码器和基于GAN的模型,它们已经包括在以前关于深度学习[6],[41]和对抗性训练[42],[43]的调查中,并进行了深入的讨论。因此,我们不会在接下来的章节中重新讨论它们。在检索相关论文时,我们使用DBLP和谷歌学术作为主要的搜索引擎,关键词为:自监督+推荐、对比性+推荐、增强+推荐、预训练+推荐。然后,我们遍历了识别出的论文的引文图,并保留了相关的论文。特别是,我们密切关注顶级会议/期刊,如ICDE、CIKM、ICDM、KDD、WWW、SIGIR、WSDM、AAAI、IJCAI、TKDE、TOIS等,以避免漏掉高质量的工作。除了这些已发表的论文,我们还对arXiv上的预印本进行了筛选,并将那些具有新颖和有趣想法的论文整理出来,以获得一个更加包容的全景图。
与现有调查的联系。虽然有一些关于图SSL的调查[35], [36], [44]包括一些关于推荐的论文,但他们只是把这些工作作为图SSL的补充应用。另一项相关的调查[45]关注了推荐模型的预训练。然而,它的重点是通过利用知识图谱在不同领域之间转移知识,并且它只涵盖了少数类似BERT的工作,这些工作是以自监督的方式进行预训练。与它们相比,我们的调查纯粹是围绕着针对推荐的SSL,并且是第一个对这一研究领域的大量最新论文进行系统回顾的调查。
读者。本调查报告将使以下推荐社区的研究人员和从业人员受益:1)刚接触自我监督并想快速进入这一领域的人;2)迷失在一系列令人困惑的自我监督应用方法中,需要对这一领域有一个纵览;3)想跟上自我监督的最新进展;4)正在开发自我监督推荐系统并寻求指导的人。
调查结构。本调查的其余部分结构如下。在第2节中,我们首先介绍了SSR的定义和表述,然后介绍了从调查大量研究论文中提炼出来的分类法。第3节介绍了常用的数据增强方法。第4-7节分别回顾了四类SSR模型并展示了它们的优点和缺点。第8节介绍了开源框架SELFRec,它有助于SSR方法的实施和比较。第9节讨论了当前研究的局限性,并指出了一些有前途的方向,以激励未来的研究。最后,第10节是本文的结论。
定义和分类法
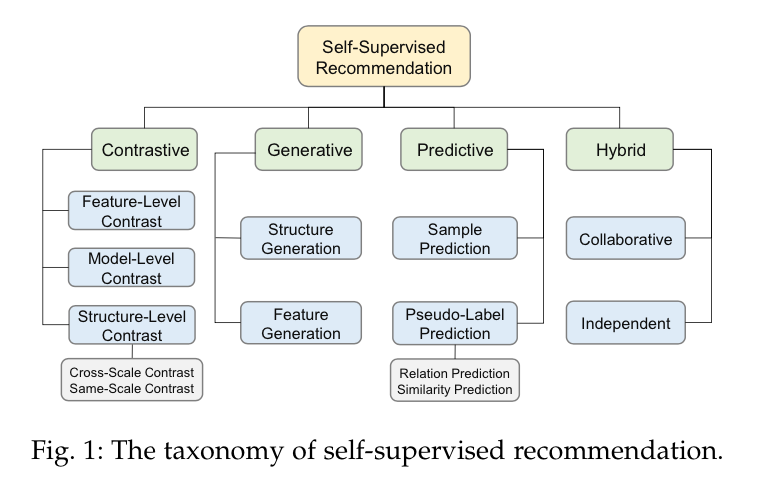
在本节中,我们首先定义并形式化了SSR。然后,我们列出了一个全面的分类法,根据其代理任务的特点,将现有的SSR方法分为四个范式(图1)。最后,我们介绍了三种典型的SSR的训练方案。
预备工作
目前SSR的研究主要是利用图和序列数据,其中原始的用户-项目互动分别被建模为双位图和按时间顺序排列的项目序列。在基于图的推荐的情况下,我们让
自监督推荐的定义
SSL提供了一种新的方法来解决推荐中的数据稀疏问题。然而,目前对SSR还没有明确的定义。参考其他领域对SSL的定义[7],[35]以及SSL在所收集的推荐文献中的功能,我们将SSR的基本特征总结为:
(i) 通过半自动地利用原始数据本身获得更多的监督信号。
(ii) 有一个或多个代理任务,用增强的数据(预)训练推荐模型。
(iii) 推荐任务是唯一的主要任务,而代理任务在加强推荐方面起辅助作用。
在这些特征中,(i)是基本的,意味着SSR的范围。(ii)说明了SSR的设置,它使SSR有别于其他推荐范式。(iii)指出了推荐任务和代理任务之间的关系。鉴于这个定义,我们可以理清基于预训练的推荐模型[45]和SSR模型之间的区别。前者经常被误解为后者的一个分支或同义词,因为在CV和NLP领域,预训练已经成为SSL的一个标准技术。然而,一些基于预训练的推荐方法[46], [47]是纯监督的,没有数据增强,他们要求额外的人类注释的侧面信息进行预训练。因此,这两种范式只是部分地重叠了。类似地,基于对比学习(CL)[27]的推荐通常被认为是SSR的一个子集。然而,CL可以应用于有监督和无监督的环境,那些基于CL的推荐方法不增加原始数据[48],[49],[50],只是优化一个边际损失[51],[52],也不应该被粗略地归入SSR。
由于推荐系统中数据和优化目标的多样性,为了正式定义SSR,需要一个模型无关的框架。虽然具体的结构和使用的编码器和投影头的数量因情况而异,但一般来说,大多数现有的模型可以被勾勒成一个编码器+投影头的架构。为了处理不同的数据,如图、序列和分类特征,各种神经网络如GNN[53]、Transformation[54]和MLPs都可以作为编码器
其中,
自监督推荐的分类法
作为SSR的关键要素,代理任务使SSR有别于其他推荐范式。根据借口任务的特点,我们将现有的SSR模型分为四类:对比型、预测型、生成型和混合型。
对比型
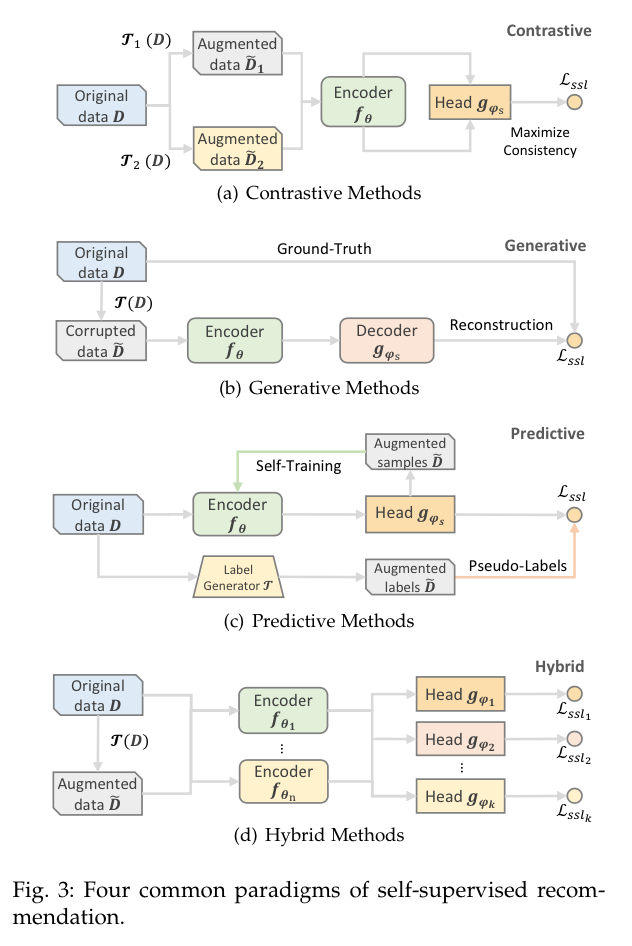
在CL[27]的推动下,对比性方法已经成为SSR的主要分支(如图2(a)所示)。对比法的基本思想是将每个实例(例如,用户/项目/序列)视为一个类,然后将同一实例的视图在嵌入空间中拉近,并将不同实例的视图推开,这些视图是通过对原始数据施加不同的变换而产生的。一般来说,同一实例的两个视图被认为是一对正视图,而不同实例的视图被认为是彼此的负样本。正视图应该是在不修改语义的情况下将非必要的变化引入实例。通过最大化正向对之间的一致性,同时最小化负向对之间的一致性,我们可以获得用于推荐的可判别的和可概括的表示。从形式上看,对比型SSR方法(图3(a))的代理任务可以定义为:
其中,
生成型
生成方法受到掩蔽语言模型(MLM)[12]的启发,其代理任务是用其损坏的版本重建原始的用户/项目概况(图3(b))。换句话说,该模型学会了从其余的可用数据中预测一部分。最常见的任务是结构重建(例如,被屏蔽的项目预测)和特征重建。在这些情况下,代理任务被表述为:
其中
预测型
预测方法通常看起来像生成方法,因为它们都有预测的作用。然而,在生成方法中,目标是预测原来存在的缺失部分,这可以被视为自我预测。而在预测性方法中,新的样本或标签是从原始数据中生成的,以指导预测任务。我们进一步将现有的预测性SSR方法分为两类:基于样本和基于伪标签(图3(c))。前者主要是根据编码器的当前参数来预测信息量大的样本,然后将这些样本再次反馈给编码器,以便生成置信度更强的新样本[55], [56]。这样一来,自我训练(半监督学习的一种风格)和SSL是相通的。基于伪标签的分支通过一个生成器产生标签,生成器可以是其他编码器或基于规则的选择器。然后,生成的标签被用作指导编码器
其中
混合型
上述每种类型的代理任务都有自己的优势,可以利用不同的自监督信号。获得全面自监督的一个自然方法是结合不同的代理任务,并将它们整合到一个推荐模型中。在这些混合方法中,可能需要一个以上的编码器和投影头(3(d))。不同的代理任务要么独立工作,要么合作,以强化自监督的信号。不同类型的借口任务的组合通常被表述为前述类别中提出的不同自监督损失的加权和。
自监督推荐的典型训练方案
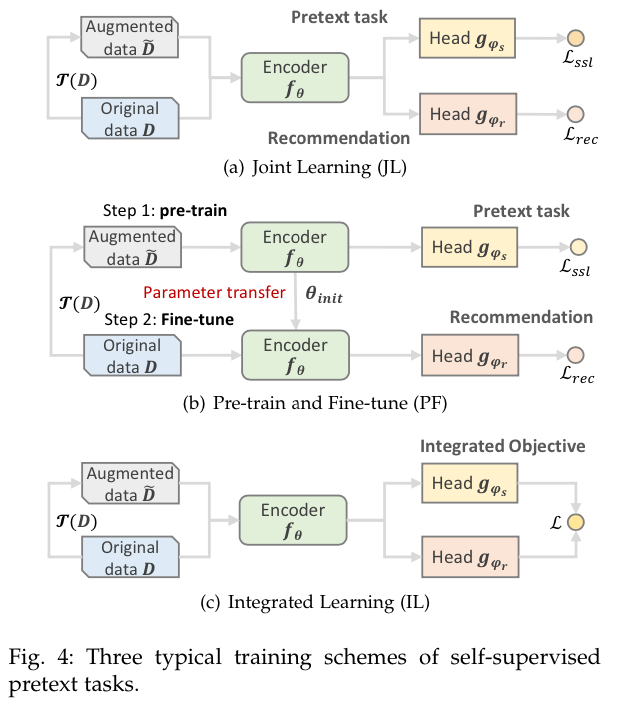
尽管SSR有统一的表述(公式(1)),但在不同的场景中,推荐任务与代理任务以更具体的方式结合起来。在本节中,我们介绍三种典型的SSR训练方案。联合学习(JL),预训练和微调(PF),以及综合学习(IL)。图4中给出了它们的简要pipelines。
联合学习
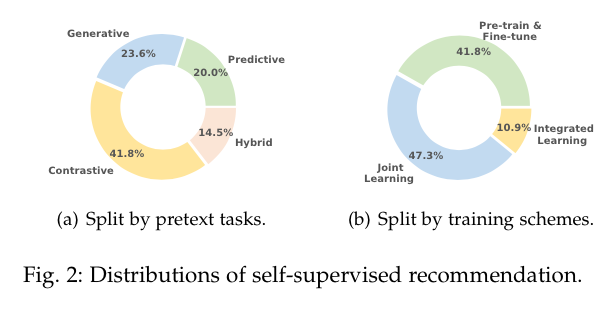
根据图2(b),在收集到的SSR方法中,近一半的方法倾向于JL训练方案。在这个方案中,通常用一个共享编码器来联合优化代理和推荐任务(图4(a))。两个目标
JL方案多用于对比性方法。
预训练和微调
PF方案是第二种最普遍的训练方案,它包括两个阶段:预训练和微调(图4(b))。在第一阶段,编码器
PF方案通常用于训练类似BERT的生成性SSR模型,这些模型在基于mask的序列增强上进行了预训练,然后在交互数据上进行了微调。一些对比性的方法也采用了这种训练方案,其中对比性的代理任务是为了预训练。
综合学习
与JL和PF方案相比,IL方案受到的关注较少,没有得到广泛的应用。在这种情况下,代理任务和推荐任务是一致的,它们被统一为一个综合目标。损失L通常测量两个输出之间的差异或相互信息。IL方案可以被形式化为如下:
IL方案主要被基于伪标签的预测方法和少数对比性方法所使用。
数据增强
之前多个领域在SSL方面的努力[57],[58],[59]已经证明了数据增强在学习高质量和可推广的表征方面起着关键的作用。在详细介绍SSR方法之前,我们总结了SSR中常用的数据增强方法,并将其分为三类:基于序列、基于图和基于特征。这些增强方法中的大多数是与任务无关的,也是与模型无关的,它们被用于SSR的不同范式中。对于那些与任务和模型相关的方法,我们将在第4-7节中与具体的SSR方法一起介绍。
基于序列的增强
给定一个项目序列
项目屏蔽。类似于BERT[12]中的单词屏蔽,项目屏蔽策略(又称项目剔除)[60], [25], [61], [62], [63]随机屏蔽一部分
项目裁剪。受CV中图像裁剪的启发,一些工作[61], [25], [62], [60]提出了项目裁剪增强法(又称序列分割)。考虑到用户的历史序列
这种方法提供了一个用户历史序列的局部视图。通过自监督的任务,所选的子序列有望赋予模型在没有全面的用户资料的情况下学习一般化表征的能力。
项目重新排序。许多顺序推荐器[64],[65],[68]假设一个序列中的项目顺序是严格的,所以项目的转换是顺序性的。然而,这个假设可能是有问题的,因为在现实世界中,许多未观察到的外部因素会影响项目的顺序[66],不同的项目顺序实际上可能与同一个用户的意图相关。有些工作[61], [60]提出将连续的子序列
项目置换。随机项目的裁剪和遮蔽会夸大短序列中的数据稀疏问题。[67]提出用高度相关的项目替代短序列中的项目,这对原始序列信息的破坏较小。给定
其中,相关项目是通过计算相关分数获得的,该分数是基于项目共现或相应表征的相似性。
项目插入。在短序列中,记录的交互不能跟踪全面的用户动态和项目关联。因此,[67]也提出在短序列中插入相关的项目来完成序列。首先从给定的序列中随机选择
基于图的增强
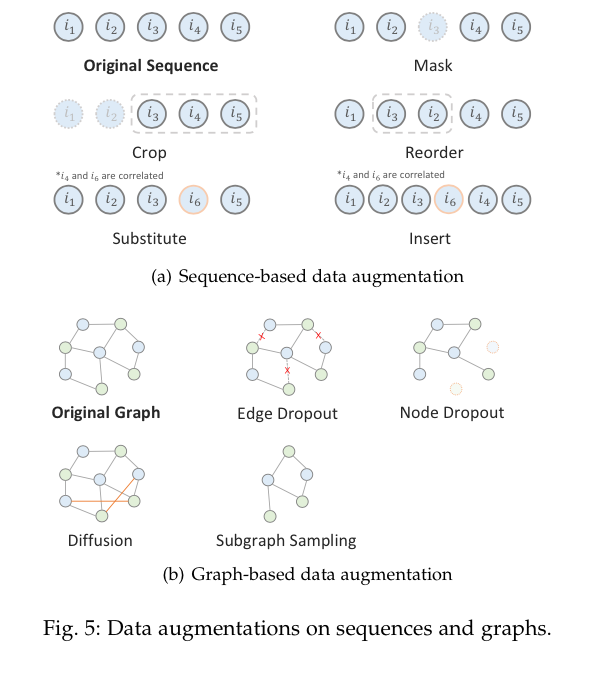
鉴于用户-物品图
边缘/节点剔除。在概率为
其中
其中
图形扩散。与基于剔除的方法相反,基于扩散的增强方法在图中添加边来创建视图。[73]认为缺失的用户行为包括未知的积极偏好,可以用加权的用户-项目边来表示。因此,他们通过计算用户和物品表示的相似性来发现可能的边,并保留具有前
当边缘是随机添加的时候,这种方法也可以用来生成负样本。
子图采样。这种方法对形成子图的一部分节点和边进行采样,反映了局部的连接性。有很多方法可以用来诱导子图,如元路径引导的随机行走[74], [70],和自我网络采样[29], [75], [76], [77]。子图抽样的基本思想类似于边缘剔除的思想,而子图抽样通常对局部结构进行操作。给出采样的节点集
基于特征的增强
基于特征的增强侧重于用户/项目特征,在属性/嵌入空间中操作。在这一部分,分类属性和学习到的连续嵌入被统称为特征,为了简洁起见,用
特征滤除。特征剔除(又称特征遮蔽)[25], [71], [78], [79], [33], [80]与项目遮蔽和边缘剔除类似,随机遮蔽/剔除一小部分特征,表述为:
其中
特征洗牌。特征洗牌[29], [28], [81]切换特征矩阵X的行和列。这种方法可以被表述为:
其中
特征聚类。这种增强方法[82],[83],[84]是CL与聚类的桥梁,它假定在特征/表征空间中存在原型,用户/项目表征应该更接近其分配的原型。增强的原型表征可以通过期望最大化(EM)框架内的聚类来学习。这种方法可以表述为:
其中
特征混合。这种增强方法[85], [71]将原始的用户/项目特征与其他用户/项目或以前版本的特征混合起来,以合成信息性的负面/正面的例子[86]。它通常以下列方式将两个样本混合在一起:
其中
对比学习的方法
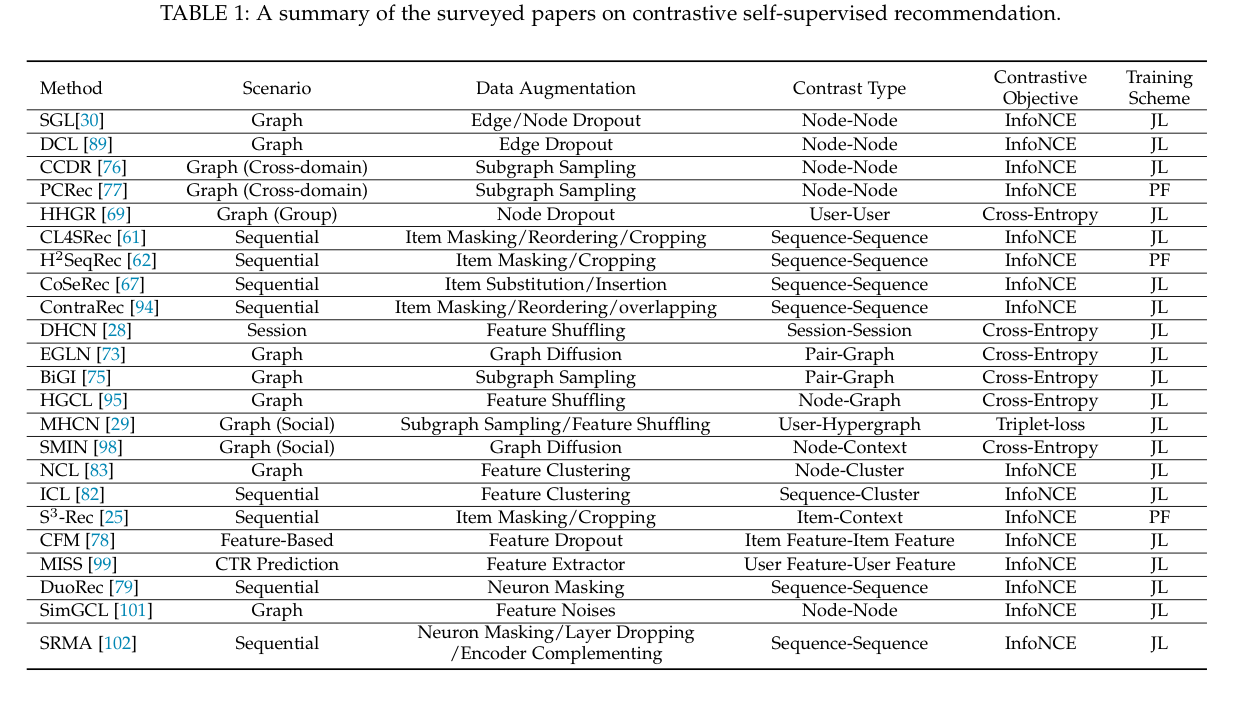
结构层面的对比
用户行为数据通常被组织成图或序列。具有轻微扰动的图/序列结构可能具有类似的语义。通过对比不同的结构,获得对结构扰动的共同不变性,作为自我监督的信号。我们借用[35]、[36]的分类法,将结构层面的对比细分为:同尺度对比和跨尺度对比。在前一类中,要对比的视图来自同一尺度的两个物体。在后者中,需要对比的视图来自不同尺度的两个物体。我们将同尺度对比进一步细分为两个层次:局部-局部和全局-全局。类似地,跨尺度对比又被分为。局部-全局,以及局部-上下文。对于图结构来说,局部指的是节点,而全局指的是图。对于序列结构,局部指的是项目,而全局指的是序列。
局部-局部对比
在基于图的SSR模型中经常进行这种类型的对比,以最大化用户/项目节点表征之间的相互信息,可以表述为:
其中
对于局部层面的对比,基于dropout的增强是创建扰动的局部视图的最优先方法。SGL[30],作为一个有代表性的基于图CL的推荐模型,在用户-项目二元图上应用了三种类型的随机图增强:节点dropout、边dropout和随机行走(多层边缘dropout)。它首先生成两个具有相同类型的增强算子的增强图。然后,它采用共享图LightGCN编码器fθ[87],从增强图中学习节点嵌入。节点级的对比是通过优化InfoNCE损失[13]和批量内负采样进行的。最后,SGL联合优化上述InfoNCE损失和贝叶斯个性化排名(BPR)损失[88]进行推荐。与SGL类似,DCL[89]也采用随机边缘丢弃来扰乱一个给定节点的L-跳自我网络,从而产生两个增强的邻域子图。然后,它最大限度地提高在这两个子图上学到的节点表征之间的一致性。
考虑到丢弃一个重要的节点可能会导致高度倾斜的局部结构,HHGR[69]提出了一种双尺度的节点丢弃方法,以在群体推荐的场景中创建有效的自我监督信号[90]。提出的粗粒度剔除方案从所有组中剔除一部分用户节点,细粒度剔除方案只从特定组中剔除随机选择的成员节点。然后,该方法将从这两个视图中学习到的用户节点表征之间的相互信息最大化,并采用不同的退出粒度。
子图抽样是局部水平图对比中另一种流行的增强方法。CCDR[76]将CL应用于跨领域推荐。它设计了两种类型的对比任务:CL内和CL间。CL内任务与DCL[89]中的对比任务几乎相同,都是在目标域内进行,并采用图注意网络[91]作为编码器。CL间任务的目的是使在源域和目标域学到的同一对象的表征之间的相互信息最大化。一个同时进行的工作PCRec[77]也将跨域推荐与CL联系起来。它用随机行走对r-hop自我网络进行采样,以增加数据。采样子图之间的对比任务在源域中预先训练了一个GIN[92]编码器。然后,参数被转移到初始化MF[93]模型,该模型用交互数据进行微调,以便在目标域进行推荐。
全局-全局对比
全局层面的对比通常在顺序推荐模型中进行,其中一个顺序被认为是一个用户的全局视图,可以表述为:
其中
CL4SRec[61]使用三种随机增强操作:项目屏蔽和项目重排操作:项目遮蔽、项目裁剪和项目重排。
扩增序列。给定
局部-全局对比
局部-全局对比有望将高层次的全局信息编码到局部结构表征中,并统一全局和局部语义。它经常被应用于图的学习场景,可以表述为:
其中
EGLN[73]提出通过对比合并后的用户-项目对表征和全局表征(所有用户-项目对表征的平均值)来达到局部-全局一致性。为了挖掘更多的自我监督信号,它采用了数据增强的图扩散法。通过计算用户和项目之间的相似性并保留top-K的相似性,得到增强的图相邻矩阵。矩阵和用户/物品的表示法相互迭代学习,并通过图编码器得到更新。在BiGI[75]中,也进行了类似的局部-整体对比。不同的是,在生成用户-项目对表示时,只有其h-hop子图(即该子图中的任何节点vk满足dist(vi,vk)≤h或dist(vj,vk)≤h)被采样用于特征聚合。在HGCL[95]中,构建了用户和物品节点类型的同质图。对于每个同质图,它遵循DGI[15]的管道,使图的局部斑块和整个图的全局表示之间的相互信息最大化。此外,还提出了一个跨类型的对比来衡量不同类型的同质图的局部和全局信息。
局部-上下文对比
在图和基于序列的情况下,都可以观察到局部与上下文的对比。语境通常是通过采样自我网络或聚类来构建的。这种类型的对比可以被表述为:
其中
NCL[83]遵循[84]设计了一个原型对比目标,以捕捉用户/项目与其原型之间的关联性。原型可以被看作是每个用户/项目的背景,它代表了一组语义上的邻居,即使它们在用户-项目图中没有结构上的联系。关于原型学习,作为数据增强的一种特征聚类,它通过用K-means算法对所有的用户或项目嵌入进行聚类而获得原型。然后用EM算法来递归调整原型。ICL[82]有几乎相同的管道,唯一的区别是ICL是为顺序推荐而设计的,其中NCL中的语义原型在ICL中被建模为用户意图,而这里的归属序列是一个局部视图的原型。
在社交网络中,用户通常与他们的拓扑环境相似。MHCN[29]是第一个将SSL应用于社交推荐的工作[96], [97]。它定义了三种类型的三角形社会关系,并用多通道超图编码器对其进行建模。对于每个通道中的每个用户,MHCN分层次地最大化用户表示、用户的自我超图表示和全局超图表示之间的实际信息。后续工作SMIN[98]继承了MHCN中的想法,将节点与它们的背景进行对比。不同的是,上下文是通过聚合来自不同顺序的用户-项目邻接矩阵链的信息而获得的。
此外,还有一些跨越不同对比度的方法。S3-Rec[25]应用了两个运算符:项目屏蔽和项目裁剪来增强序列。然后,它设计了四个对比任务:项目-属性相互信息最大化(MIM)、序列-项目MIM、序列-属性MIM,以及序列-序列MIM,以预先训练一个用于下一个项目预测的双向Transformer。
特征级别对比
与结构级对比相比,特征级对比的探索相对较少,因为在学术用途的数据集中,并不总是有特征/属性信息。然而,在工业领域,数据通常是以多字段格式组织的,大量的分类特征,如用户资料和项目类别,都可以被利用。一般来说,这种类型的对比可以正式定义为:
其中
CFM[78]采用了一个双塔结构,并在项目特征上应用相关的特征屏蔽和剔除,以获得更有意义的特征增强。它试图将高度相关的特征掩盖在一起,这些特征的相关性是通过互信息来衡量的。因此,对比任务变得很困难,因为保留的特征很难补救被屏蔽的特征背后的语义。MISS[99]认为,一个用户行为序列可能包含多种兴趣,直接扰动序列会导致语义上的不同增强。相反,它使用一个基于CNN的多兴趣提取器,将包含行为数据和分类特征的用户样本转化为一组隐含的兴趣表征,在特征层面上增强用户样本。然后在提取的兴趣表征上进行对比性任务。
模型级别
前两类从数据角度提取自我监督信号,并没有完全以端到端的方式实现。另一种方式是保持输入不变,动态地修改模型架构,使视图对得到即时增强。这些模型级的增强之间的对比可以正式定义为:
其中
神经元屏蔽是一种常用的扰动模型的技术。DuoRec[79]沿用了SimCSE[100]的成功经验,将两套不同的丢弃掩码应用于基于Transformer的骨干模型,进行两个模型级的表示增强。然后,它使这两个表征之间的互信息最大化。虽然它看起来惊人的简单,但这种方法在下一个项目的预测任务中显示出明显的性能。与神经元掩蔽法相反,SimGCL[101]直接在隐性表征中加入随机均匀噪声进行增强。实验证明,优化InfoNCE损失实际上可以学习到更多的均匀节点表征,调整噪声大小可以对表征的均匀性进行更精细的调节,从而缓解了流行偏向问题[39]。受益于基于噪声的增强,SimGCL在推荐精度和模型训练效率上都比SGL显示出明显的优势。在SRMA[102]中,除了神经元级别的扰动,它还提议在训练中随机放弃一部分层。考虑到放弃重要的层会误导输出,它随机放弃了Transformer中前馈网络的一些层来进行模型级的增强。此外,它还进一步引入了另一个预训练的编码器,该编码器具有相同的结构,但通过推荐任务进行训练,以产生不同的视图进行对比。
在分类法之外,还有一些论文[103]、[104]声称他们提出的方法是对比性的自我监督。他们处理多行为数据,并通过纳入辅助行为数据作为监督信号来进行数据增强。同一用户的行为观点被认为是正数对,而不同用户的观点被抽样为负数对。然后,这些方法通过进行行为层面的对比,鼓励正向对的表述之间的一致性。然而,我们认为称它们为自我监督是牵强的,因为它们事实上并没有为创建任何新的观点而转换原始数据。
对比损失
对比性损失已经成为CV领域的一个新的研究热点,在SSR领域也越来越受到关注。一般来说,对比性损失的优化目标是最大化两个表征(视图)
然而,直接最大化MI是困难的,一个实用的方法是最大化其下限。在本节中,我们回顾了两个最常用的下限。Jensen-Shannon估计器[105]和Noise-Contrastive估计器(又称InfoNCE[13])。
···
生成性的方法
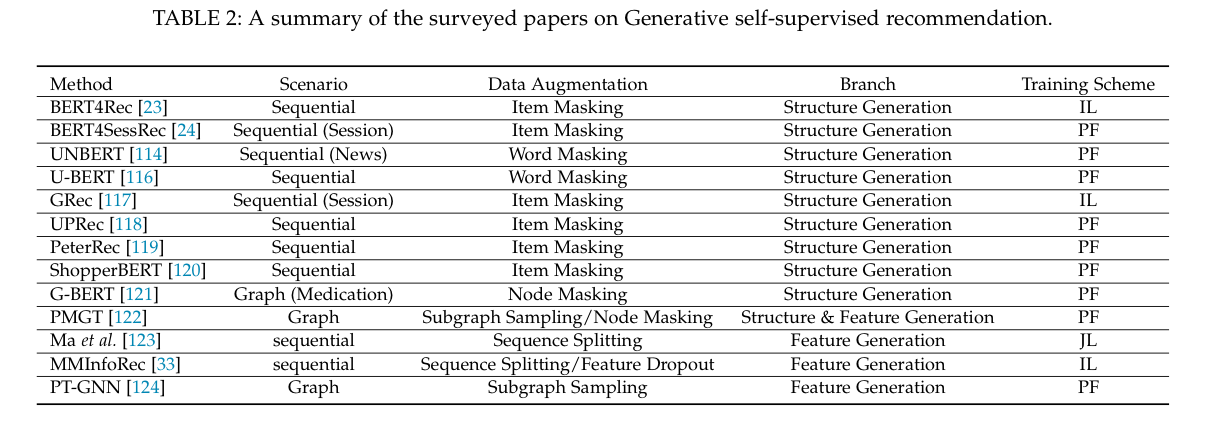
生成式SSR方法是基于这样的想法:通过用损坏的版本重建原始输入,数据中的内在关联性可以被编码,从而有利于推荐任务。在本节中,我们主要关注基于MLM的生成性SSR方法,这是目前的趋势之一。根据重建目标,我们将生成式SSR方法分为两类:结构生成和特征生成。
结构生成
这个分支的方法利用结构信息来监督模型。通过对原始结构应用基于掩蔽/丢弃的增强运算符(见第3节),可以得到其损坏的版本。在基于序列的推荐方案中,恢复结构可以被表述为:
其中,
BERT4Rec[23]是BERT[12]在顺序推荐中的第一个实例化。顺序推荐的第一个实例(BERT4SessRec[24]是一个同时进行的工作,想法几乎相同)。它升级了SASRec[113]中从左到右的训练方案,并提议学习一个双向的表示模型。从技术上讲,它随机地掩盖了输入序列中的一些项目,然后根据其周围的项目来预测这些被掩盖的项目的ID。为了使预测阶段与训练阶段保持一致,它在输入序列的末尾加上标记[mask]以表示要预测的项目。该目标被表述为:
其中
受BERT4Rec的成功启发,后续工作将遮蔽项预测训练应用到更具体的场景中。UNBERT[114]和Wu等人[115]以几乎相同的方式探索将这种技术用于新闻推荐。UNBERT的输入是新闻句子和用户句子与一组特殊符号的组合。它随机地掩盖了一些词片标记,用Cloze任务预训练标记表征,然后在新闻推荐任务上对模型进行微调。另一项类似的工作U-BERT[116]使用评论评论来预训练源域中的屏蔽词-标记-预测的编码器,然后在目标域中用一个附加层对编码器进行微调,因为评论不足以进行评级预测。GRec[117]在编码器-解码器的设置上开发了一种缺口填补机制。编码器将部分完整的会话序列作为输入,解码器根据编码器的输出和自己的完整嵌入来预测被屏蔽的项目。UPRec[118]进一步修改了BERT4Rec,使其能够利用用户属性和社交网络等异质信息来增强序列的建模。
虽然上述生成式模型取得了可喜的成果,但它们主要是针对一种类型的推荐任务进行预训练。还有一条研究路线,其目标是通过生成式预训练学习通用表示法[125], [119], [120],从而使多种下游推荐任务受益。PeterRec[119]首次尝试将遮盖项目预测预训练的模型参数转移到与用户相关的任务中。它没有对预训练的参数进行微调,而是将一系列小的嫁接神经网络注入到预训练的原始模型中,并且只训练这些补丁以适应特定的任务。类似地,ShopperBERT[120]用九个生成性预案任务进行了预训练,包括掩饰性购买预测,学到的通用用户表征可以服务于六个下游的推荐相关任务。受益于大规模的预训练数据集,它显示出比从头开始学习的基于特定任务的Transformer模型的优越性。
在基于图的推荐方案中,结构生成方法被表述为:
G-BERT[121]结合了GNNs和BERT的力量,用于药物推荐。它将电子健康记录中的诊断和药物代码建模为两个树状图,并采用GNNS来学习图的表示。然后,这些表征被送入BERT编码器,并通过两个生成性预言任务进行预训练:自我预测和双重预测。自我预测任务用同一类型的图重建被屏蔽的代码,而双重预测任务用另一种类型的图重建被屏蔽的代码。PMGT[122]用采样的子图进行图的重建任务。它开发了一种抽样方法,对每个项目节点进行子图抽样,并根据邻居的重要性将抽样的子图重组为一个有序的序列。然后,子图被送入一个基于转化器的编码器,该方法用缺失的相邻项目预测对项目表征进行预训练。
特征生成
特征生成任务可以被表述为:
其中
在PMGT[122]中,除了图重构任务,特征重构任务也被用来预设基于转化器的推荐模型。该方法事先提取物品的文本和图像特征,并用提取的特征初始化物品嵌入。然后,它对部分采样节点进行屏蔽,并使用其余节点来恢复被屏蔽节点的特征。至于序列特征的生成,Ma等人[123]提出用过去的行为重构未来序列的表示。具体来说,他们分解了任何给定的行为序列背后的意图,并且在任何涉及共同意图的子序列对之间进行重建。同样,在MMInfoRec[33]中,给定一个有t个项目的序列,它对该序列进行编码并预测下一个项目在时间步骤t+1的表示。然后,增强的序列表示与真实的t+1项的表示(ground-truth)进行对比。一个自回归预测模块被设计用来包括更多的未来信息,通过预测t+k项目与项目t+1到项目t+i-1。编码器中使用了一个剔除功能,以创建多个语义相似的项目表征来提高CL。
为了加强冷启动用户和项目的表示,PTGNN[124]提出通过模仿元学习的设置来预训练GNN模型。它挑选有足够互动的用户/物品作为目标用户/物品,并对目标用户的K个邻居进行图卷积,以预测他们从整个图中学习的真实嵌入。优化这种重构损失直接提高了嵌入能力,使该模型容易并迅速适应冷启动用户/项目。
优点和缺点
最新的生成性SSR方法大多遵循屏蔽语言模型的管道。依靠这个标准的管道和Transformer的能力,这些方法已经显示出显著的效果。BERT在大规模语料库中的成功训练经验也为基于MLM的大型推荐模型的应用铺平了道路。然而,这个分支的方法可能会面临繁重的计算挑战。由于大多数开源数据集的规模较小,基于变换器的生成方法通常采用一层或两层的设置。然而,当用大规模的数据集进行新闻推荐或通用表示法的训练时,计算量大得惊人。特别是,考虑到扩展预训练数据集确实有帮助,在性能和高计算开销之间会有一个两难的选择,特别是对于那些计算资源有限的研究小组。
预测性方法
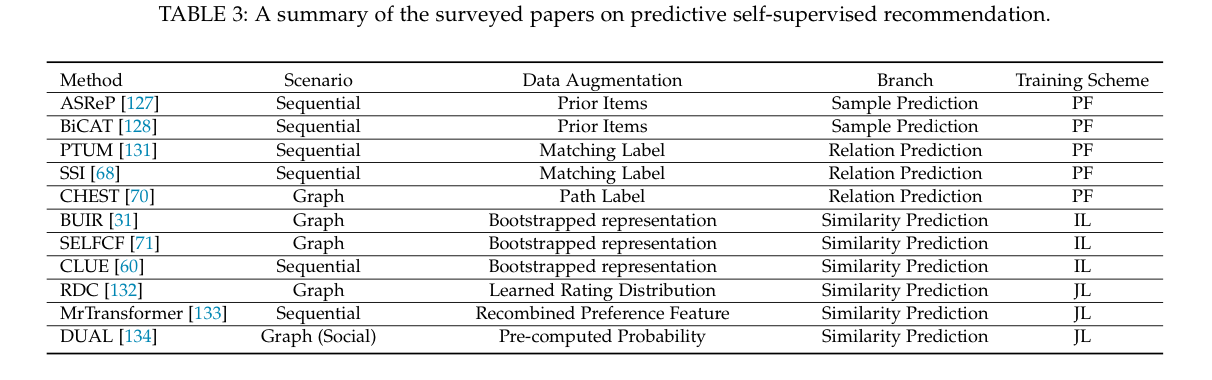
与破坏原始数据以获得自我监督的生成性SSR方法不同,预测性SSR方法处理的是由完整的原始数据获得的自我生成的监督信号。根据预测性借口任务预测的内容,我们将预测性方法分为两个分支。样本预测和伪标签预测。
样本预测
在这个分支下,自我训练[126](半监督学习的一种风格)与SSL有关。SSR模型首先用原始数据进行预训练。基于预训练的参数,模型预测出对推荐任务有参考价值的潜在样本。获得的样本作为增强的数据,然后被送入模型以增强推荐任务或递归地产生更好的样本。基于SSL的样本预测和纯粹的自我训练之间的区别在于,在半监督学习的设置中,有限数量的无标签样本已经准备就绪,而在SSL的设置中,样本是动态生成的。
由于用户行为有限,顺序推荐模型在短序列上的表现往往很差。为了提高模型的性能,ASReP[127]提出用伪优先项目来增强短序列。给定从左到右的时间顺序的序列,ASRep首先以相反的方式(即从右到左)预训练一个基于转化器的编码器SASRec[113],以便该编码器能够预测伪优先级项目。然后得到一个增强的序列(例如,
在图的情况下,样本也可以根据节点特征/语义的相似性进行预测。当有多个编码器建立在不同的图上时,它们可以递归地预测其他编码器的样本,其中自我训练被升级为共同训练[129]。在SEPT[56]和COTREC[55]中,提出了这样的想法。我们在第7节中介绍它们,因为这些方法集合了多个代理任务。
伪标签预测
在这个分支下,伪标签以两种形式呈现:预先定义的离散值和预先计算/学习的连续值。前者通常描述两个对象之间的一种关系。相应的代理任务的目标是预测给定的一对对象之间是否存在这种关系。后者通常描述了给定对象的属性值(例如,节点度[130])、概率分布或特征向量。相应的预言任务旨在最小化输出和预先计算的连续值之间的差异。我们可以将这两个预测任务表述为。关系预测和相似性预测。
关系预测
关系预测任务可以被表述为一个分类问题,其中预先定义的关系,作为他的伪标签,在没有任何成本的情况下自动自我生成。我们可以细化公式(4)来提供这个方法分支的表述,即:
其中
受BERT[12]中的下一句预测(NSP)的启发(即预测B句是否在A句之后),一些预测性的自监督顺序推荐模型提出了预测两个序列之间的关系。PTUM[131]重复了BERT中的NSP,将用户行为序列分成两个不重叠的子序列,分别代表过去行为和未来行为。然后,它根据过去的行为来预测一个候选行为是否是未来的行为。SSI[68]通过一个预设任务对基于转换的推荐模型进行预训练,该任务将给定序列中的部分项目进行打乱/替换,然后预测修改后的序列是否符合原始顺序/来自同一用户。
在图的情况下,伪关系通常是通过随机行走建立的。CHEST[70]提出在异质的用户-项目图上进行预定义的基于元路径的随机行走,以连接用户-项目对。它认为元路径类型预测是一项预测性任务,以预先训练一个基于Transformer的推荐模型。给定一个用户项目对,预案任务预测它们之间是否存在特定元路径的路径实例。
相似性预测
相似性预测任务可以被表述为一个回归问题,其中预先计算/学习的连续值作为模型的输出需要近似的目标。我们可以细化公式(4),为这个方法分支提供如下表述:
其中
BUIR[31]是一种有代表性的预测性SSR方法,它模仿视觉模型BYOL[9],依靠两个不对称的图编码器,被称为在线和目标网络,在没有负采样的情况下相互监督。给定一个用户-物品对,在线网络被输入用户表示,并被训练来预测目标网络输出的物品表示,反之亦然。通过这种方式,BUIR通过booststrapping表征实现自我监督,这意味着使用估计值来估计其目标值。特别是,在线网络以端到端的方式更新,而目标编码器则通过基于动量的移动平均来缓慢地接近在线编码器,这鼓励了在线编码器提供增强的表示作为目标。SelfCF[71]继承了BUIR的优点,并通过在两个网络中只使用一个共享编码器进一步简化了它。为了获得更多的监督信号来学习辨别性的表征,它对目标网络的输出进行了扰动。另一个非常类似的并行工作CLUE[60],是BYOL[9]在顺序推荐中的实例,也采用了一个共享编码器。SELFCF和CLUE的主要管道区别是CLUE增强了输入,而SELF增强了输出表示。
当涉及到异质信息图时,相似性预测任务也可以用来捕捉丰富的语义。在DUAL[134]中,进行了连接用户-项目对的基于元路径的随机行走。对于每个用户-项目对,元路径实例的数量被记录下来,并按比例来衡量该对的交互概率。然后,分配一个路径回归借口任务来预测预先计算的概率,并期望将路径语义整合到节点表示中以加强推荐。
优点和缺点
与对比性方法和生成性方法相比,预测性方法主要依靠静态的增强运算符,以更加动态和灵活的方式获取样本和伪标签。特别是,样本的预测是基于不断变化的模型参数,这直接完善了自我监督的信号,并使其与优化目标相一致,可能会导致更好的推荐性能。然而,我们也应该对使用预先增强的标签持谨慎态度。大多数现有的方法都是基于启发式方法来收集伪标签,而没有评估这些标签和预测任务与推荐的相关性。考虑到用户与项目的互动以及相关的属性/关系产生的理由(如社会动态),有必要将专家知识作为先验纳入伪标签的收集,这增加了开发预测性SSR方法的费用。
混合方法
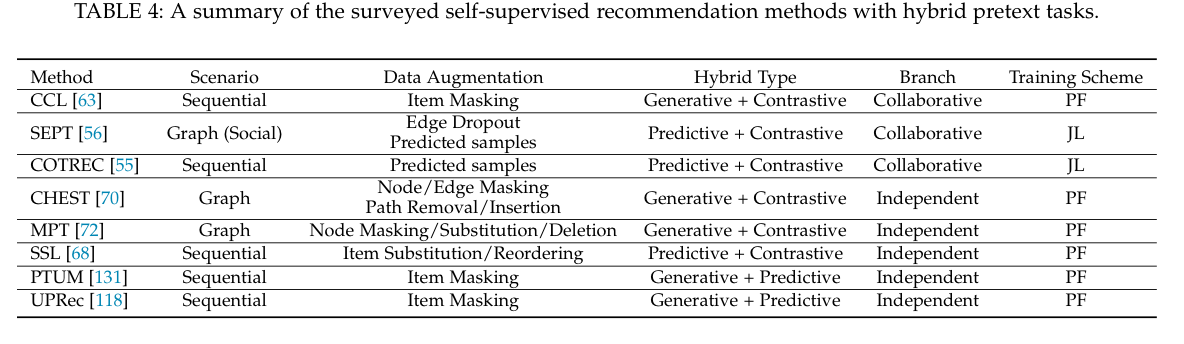
混合方法集合了多个代理任务,以利用各种类型的监督信号。我们将调查的混合方法根据其代理任务的功能分为两组,包括协作式和独立式。表4列出了所调查的对比性方法的摘要。
协作式
在这个分支下,不同的代理任务以一种合作的方式进行,其他代理任务往往通过创造更多的信息样本来为对比性的代理任务服务。
CCL[63]提出了一种课程学习[136]策略,通过将生成性代理任务与顺序推荐的对比性代理任务联系起来,预先训练基于Transformer的模型。给定一个序列,生成性任务是对被掩盖的项目进行预测。通过预测的概率,该方法对项目进行抽样,以填补序列增强的遮蔽部分。然后,这些增强的序列被送入对比任务,与原始序列进行对比。根据增强序列恢复用户属性信息的能力,它们被分为n个仓,以进行从易到难的对比过程安排。
预测性任务也可以为下游的对比性任务服务。SEPT[56]是第一个SSR模型,它通过基于样本的社会推荐预测任务,将SSL和tri-training[137](一种特殊的半监督学习)统一起来。它在具有不同社会语义的三个视图上建立了三个图形编码器(一个用于推荐),任何两个编码器都可以为其他编码器预测语义相似的样本。这些样本作为补充的积极的自我监督信号被纳入链接对比任务中,以改进编码器。改进后的编码器反过来又递归地预测更多的信息样本。COTREC[55]沿用了SEPT的框架,并将用于基于会话的推荐的编码器数量减少到两个。这两个编码器建立在两个会话诱导的时间图上,并通过对比任务迭代预测样本,以改善彼此。为了防止基于两个编码器的协同训练中的模式崩溃问题[129],它对两个编码器施加了一个发散约束,通过利用对抗性例子[138]来保持它们的微小差异。
独立式
在这个分支下,不同的代理任务之间没有关联,它们独立工作。
与CCL[63]类似,CHEST[70]也将课程学习与SSL联系起来,在异质信息网络上预训练一个基于Transformer的推荐模型。然而,它的前文任务是没有联系的。给定用户-物品图和相关属性,CHEST进行基于元路径的随机行走,从用户节点开始,以物品节点为终点,形成特定的交互子图,每个子图由多个元路径实例组成。CHEST中的生成任务预测子图中的遮蔽节点/边缘与其他节点/边缘,这利用了当地的环境信息,被认为是初级课程。对比性任务通过拉近原始子图和增强的子图来学习用户-项目交互的子图级语义,这利用了全局的关联性,被认为是高级课程。MPT[72]扩展了PT-GNN[124],它在生成性借口任务中只考虑用户和物品子图内的相互关系,以增强冷启动推荐的表示能力。为了捕捉不同子图之间的相互关系,它增加了在图上执行的对比性借口任务和基于随机行走的序列,其中节点的删除/替换/屏蔽被用来增加训练GNN和基于变换器的编码器的数据。对比性任务和生成性任务以各自的参数平行进行。最后,对参数进行合并和微调以进行推荐。
除了生成性任务和对比性任务的结合,SSI[68]集合了一个基于标签的预测性任务和一个对比性任务来预先训练模型以进行序列推荐。给定一个序列,通过预测学习施加两个一致性约束:时间上的一致性和角色的一致性。对于时间上的一致性,该方法需要预测输入的序列是按原来的顺序还是经过洗牌。对于角色一致性,它需要区分输入序列是来自某个用户,还是用不相关的项目替换了某些项目。同时,在被屏蔽的项目表示和序列表示之间进行基于项目屏蔽的对比。至于生成和预测任务的结合,在PTUM[131]中可以看到,它模仿BERT[12]来进行被遮蔽项的生成任务和下一个项的预测任务。此外,UPRec[118]将BERT与异质用户信息相连接,并通过社会关系和用户属性预测任务对编码器进行并行的预训练。
selfrec:一个用于自监督推荐的库
结论
引用
[1] F. Ricci, L. Rokach, and B. Shapira, “Introduction to recommender systems handbook,” in Recommender systems handbook. Springer, 2011, pp. 1–35.
[2] P. Covington, J. Adams, and E. Sargin, “Deep neural networks for youtube recommendations,” in RecSys, 2016, pp. 191–198.
[3] H.-T. Cheng, L. Koc, J. Harmsen, T. Shaked, T. Chandra, H. Arad- hye, G. Anderson, G. Corrado, W. Chai, M. Ispir et al., “Wide & deep learning for recommender systems,” in Proceedings of the 1st workshop on deep learning for recommender systems, 2016, pp. 7–10.
[4] G. Zhou, X. Zhu, C. Song, Y. Fan, H. Zhu, X. Ma, Y. Yan, J. Jin, H. Li, and K. Gai, “Deep interest network for click-through rate prediction,” in KDD, 2018, pp. 1059–1068.
[5] B. M. Sarwar, Sparsity, scalability, and distribution in recommender systems. University of Minnesota, 2001.
[6] S. Zhang, L. Yao, A. Sun, and Y. Tay, “Deep learning based recommender system: A survey and new perspectives,” ACM Computing Surveys (CSUR), vol. 52, no. 1, pp. 1–38, 2019.
[7] X. Liu, F. Zhang, Z. Hou, L. Mian, Z. Wang, J. Zhang, and J. Tang, “Self-supervised learning: Generative or contrastive,” IEEE TKDE, 2021.
[8] K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick, “Momentum con- trast for unsupervised visual representation learning,” in CVPR, 2020, pp. 9729–9738.
[9] J.-B. Grill, F. Strub, F. Altche ́, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. A. Pires, Z. D. Guo, M. G. Azar et al., “Bootstrap your own latent: A new approach to self- supervised learning,” arXiv preprint arXiv:2006.07733, 2020.
[10] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in ICML. PMLR, 2020, pp. 1597–1607.
[11] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Sori- cut, “Albert: A lite bert for self-supervised learning of language representations,” arXiv preprint arXiv:1909.11942, 2019.
[12] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre- training of deep bidirectional transformers for language under- standing,” arXiv preprint arXiv:1810.04805, 2018.
[13] A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” arXiv preprint arXiv:1807.03748, 2018.
[14] J. Qiu, Q. Chen, Y. Dong, J. Zhang, H. Yang, M. Ding, K. Wang, and J. Tang, “Gcc: Graph contrastive coding for graph neural network pre-training,” in KDD, 2020, pp. 1150–1160.
[15] P. Velickovic, W. Fedus, W. L. Hamilton, P. Lio`, Y. Bengio, and R. D. Hjelm, “Deep graph infomax.” in ICLR (Poster), 2019.
[16] Y. Wu, C. DuBois, A. X. Zheng, and M. Ester, “Collaborative denoising auto-encoders for top-n recommender systems,” in WSDM, 2016, pp. 153–162.
[17] S. Li, J. Kawale, and Y. Fu, “Deep collaborative filtering via marginalized denoising auto-encoder,” in CIKM, 2015, pp. 811–820.
[18] M. Gao, L. Chen, X. He, and A. Zhou, “Bine: Bipartite network embedding,” in SIGIR, 2018, pp. 715–724.
[19] C. Zhang, L. Yu, Y. Wang, C. Shah, and X. Zhang, “Collaborative user network embedding for social recommender systems,” in
ICDM. SIAM, 2017, pp. 381–389.
[20] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adver-sarial nets,” in NeurIPS, 2014, pp. 2672–2680.
[21] Q. Wang, H. Yin, H. Wang, Q. V. H. Nguyen, Z. Huang, and L. Cui, “Enhancing collaborative filtering with generative aug-mentation,” in KDD, 2019, pp. 548–556.
[22] J. Yu, H. Yin, J. Li, M. Gao, Z. Huang, and L. Cui, “Enhance social recommendation with adversarial graph convolutional
networks,” IEEE TKDE, 2020.
[23] F. Sun, J. Liu, J. Wu, C. Pei, X. Lin, W. Ou, and P. Jiang, “Bert4rec:
Sequential recommendation with bidirectional encoder represen-tations from transformer,” in KDD, 2019, pp. 1441–1450.
[24] X. Chen, D. Liu, C. Lei, R. Li, Z.-J. Zha, and Z. Xiong, “Bert4sessrec: Content-based video relevance prediction with bidirectional encoder representations from transformer,” in ACM Multimedia, 2019, pp. 2597–2601.
[25] K. Zhou, H. Wang, W. X. Zhao, Y. Zhu, S. Wang, F. Zhang,Z. Wang, and J.-R. Wen, “S3-rec: Self-supervised learning for sequential recommendation with mutual information maximiza- tion,” in CIKM, 2020, pp. 1893–1902.
[26] P. Goyal, M. Caron, B. Lefaudeux, M. Xu, P. Wang, V. Pai, M. Singh, V. Liptchinsky, I. Misra, A. Joulin et al., “Self- supervised pretraining of visual features in the wild,” arXiv preprint arXiv:2103.01988, 2021.
[27] A. Jaiswal, A. R. Babu, M. Z. Zadeh, D. Banerjee, and F. Makedon, “A survey on contrastive self-supervised learning,” Technologies, vol. 9, no. 1, p. 2, 2021.
[28] X. Xia, H. Yin, J. Yu, Q. Wang, L. Cui, and X. Zhang, “Self- supervised hypergraph convolutional networks for session- based recommendation,” in AAAI, 2021, pp. 4503–4511.
[29] J. Yu, H. Yin, J. Li, Q. Wang, N. Q. V. Hung, and X. Zhang, “Self- supervised multi-channel hypergraph convolutional network for social recommendation,” in WWW, 2021, pp. 413–424.
[30] J. Wu, X. Wang, F. Feng, X. He, L. Chen, J. Lian, and X. Xie, “Self- supervised graph learning for recommendation,” in SIGIR, 2021, pp. 726–735.
[31] D. Lee, S. Kang, H. Ju, C. Park, and H. Yu, “Bootstrapping user and item representations for one-class collaborative filtering,” arXiv preprint arXiv:2105.06323, 2021.
[32] X. Xin, A. Karatzoglou, I. Arapakis, and J. M. Jose, “Self- supervised reinforcement learning for recommender systems,” in SIGIR, 2020, pp. 931–940.
[33] R. Qiu, Z. Huang, and H. Yin, “Memory augmented multi- instance contrastive predictive coding for sequential recommen- dation,” in ICDM, 2021.
[34] L. Jing and Y. Tian, “Self-supervised visual feature learning with deep neural networks: A survey,” IEEE TPAMI, 2020.
[35] L. Wu, H. Lin, Z. Gao, C. Tan, S. Li et al., “Self-supervised on graphs: Contrastive, generative, or predictive,” arXiv preprint arXiv:2105.07342, 2021.
[36] Y. Liu, S. Pan, M. Jin, C. Zhou, F. Xia, and P. S. Yu, “Graph self- supervised learning: A survey,” arXiv preprint arXiv:2103.00111, 2021.
[37] Y. Xie, Z. Xu, J. Zhang, Z. Wang, and S. Ji, “Self-supervised learning of graph neural networks: A unified review,” arXiv preprint arXiv:2102.10757, 2021.
[38] H. Yin, B. Cui, J. Li, J. Yao, and C. Chen, “Challenging the long tail recommendation,” VLDB, vol. 5, no. 9, pp. 896–907, 2012.
[39] J. Chen, H. Dong, X. Wang, F. Feng, M. Wang, and X. He, “Bias and debias in recommender system: A survey and future directions,” arXiv preprint arXiv:2010.03240, 2020.
[40] W.-C. Kang, D. Z. Cheng, T. Yao, X. Yi, T. Chen, L. Hong, and E. H. Chi, “Learning to embed categorical features without embedding tables for recommendation,” in KDD, 2021, pp. 840–850.
[41] L. Wu, X. He, X. Wang, K. Zhang, and M. Wang, “A sur- vey on neural recommendation: From collaborative filtering to content and context enriched recommendation,” arXiv preprint arXiv:2104.13030, 2021.
[42] M. Gao, J. Zhang, J. Yu, J. Li, J. Wen, and Q. Xiong, “Recom- mender systems based on generative adversarial networks: A problem-driven perspective,” Information Sciences, vol. 546, pp. 1166–1185, 2021.
[43] Y. Deldjoo, T. D. Noia, and F. A. Merra, “A survey on adversarial recommender systems: from attack/defense strategies to gener- ative adversarial networks,” ACM Computing Surveys (CSUR), vol. 54, no. 2, pp. 1–38, 2021.
[44] J. Xia, Y. Zhu, Y. Du, and S. Z. Li, “A survey of pretraining on graphs: Taxonomy, methods, and applications,” arXiv preprint arXiv:2202.07893, 2022.
[45] Z. Zeng, C. Xiao, Y. Yao, R. Xie, Z. Liu, F. Lin, L. Lin, and M. Sun, “Knowledge transfer via pre-training for recommendation: A review and prospect,” Frontiers in big Data, vol. 4, 2021.
[46] Z. Meng, S. Liu, C. Macdonald, and I. Ounis, “Graph neural pre-training for enhancing recommendations using side informa- tion,” arXiv preprint arXiv:2107.03936, 2021.
[47] G. d. S. P. Moreira, S. Rabhi, R. Ak, M. Y. Kabir, and E. Oldridge, “Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation,” arXiv preprint arXiv:2107.05124, 2021.
[48] A. Sankar, Y. Wu, Y. Wu, W. Zhang, H. Yang, and H. Sundaram, “Groupim: A mutual information maximization framework for neural group recommendation,” arXiv preprint arXiv:2006.03736, 2020.
[49] Y. Wei, X. Wang, Q. Li, L. Nie, Y. Li, X. Li, and T.-S. Chua, “Contrastive learning for cold-start recommendation,” in ACM Multimedia, 2021, pp. 5382–5390.
[50] C. Lei, Y. Liu, L. Zhang, G. Wang, H. Tang, H. Li, and C. Miao, “Semi: A sequential multi-modal information transfer network for e-commerce micro-video recommendations,” in KDD, 2021, pp. 3161–3171.
[51] Y. Qin, P. Wang, and C. Li, “The world is binary: Contrastive learning for denoising next basket recommendation,” in SIGIR, 2021, pp. 859–868.
[52] C. Zhou, J. Ma, J. Zhang, J. Zhou, and H. Yang, “Contrastive learning for debiased candidate generation in large-scale recom- mender systems,” in KDD, 2021, pp. 3985–3995.
[53] Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Y. Philip, “A comprehensive survey on graph neural networks,” IEEE TNNLS, 2020.
[54] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez,E. Kaiser, and I. Polosukhin, " Attention is all you need," in NeurlPS, 2017, Pp. 5998-6008.
[55] X. Xia, H. Yin, J. Yu, Y. Shao, and L. Cui, "Self-supervised graph co-training for session-based recommendation,” in CIKM, 2021.
[56] J. Yu, H. Yin, M. Gao, X. Xia, X. Zhang, and N. Q. V. Hung, "Socially-aware self-supervised tri-training for recommenda- tion,” in KDD. ACM, 2021, pp. 2084-2092.
[571 K. Ding, Z. Xu, H. Tong, and H. Liu, "Data augmentation for deep graph learning: A survey” arXio preprint arXiv:2202.08235, 2022.
[581 B. Li, Y. Hou, and W. Che, "Data augmentation approaches in natural language processing: A survey,” arXio preprint arXiv:2110.01852, 2021.
[59] Y. Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola, "What makes for good views for contrastive learning?" NewrlPS, vol. 33, Pp. 6827-6839, 2020.
[60] M. Cheng, F. Yuan, Q. Liu, X. Xin, and E. Chen, “Learning transferable user representations with sequential behaviors via contrastive pre-training," in ICDM. IEEE, 2021, Pp. 51-60.
[61] X. Xie, Sun, Z. Liu, S. Wu, J. Gao, B. Ding, and B. Cui, "Con- trastive learning for sequential recommendation,” arXio preprint arXiv:2010.14395, 2020.
[62] Y. Li, H. Chen, X. Sun, Z. Sun, L. Li, L. Cui, P. S. Yu, and G. Xu, "Hyperbolic hypergraphs for sequential recommendation,” in CIKM, 2021, PP. 988-997.
[63] S. Bian, W. X. Zhao, K. Zhou, 1 Cai, Y. He, C. Yin, and J.-R. Wen, "Contrastive curriculum learing for sequential user behavior modeling via data augmentation,”" in CIKM, 2021, Pp. 3737-3746.
[64] B. Hidasi, A. Karatzoglou, L. Baltrunas, and D. Tikk, "Session- based recommendations with recurrent neural networks," in ICLR, 2016.
[65] S. Rendle, C. Freudenthaler, and L. Schmidt-Thieme, ”Factorizing personalized markov chains for next-basket recommendation,"” in WWW, 2010, pp. 811-820.
[66] S. Wang, L. Hu, Y. Wang, L. Cao, Q. Z. Sheng, and M. 4 Orgun, "Sequential recommender systems: Challenges, progress and prospects,” in IICAl, 2019, Pp. 6332-6338.
[67] Z. Liu, Y. Chen, J. Li, P. S. Yu, J. McAuley, and C. Xiong, "Con- trastive self-supervised sequential recommendation with robust augmentation,” arXiu preprint arXio:2108.06479, 2021.
[68] X. Yuan, H. Chen, Y. Song, X. Zhao, and Z. Ding, "Improving sequential recommendation consistency with self-supervised im- itation,” in ICAl, 2021, Pp. 3321-3327.
[69] J. Zhang, M. Gao, J. Yu, L. Guo, Li, and H. Yin, "Double- scale self-supervised hypergraph leaming for group recommen- dation,” in CIKM, 2021.
[70] H. Wang, K. Zhou, W. X. Zhao, J. Wang, and J.-R. Wen, "Curricu- lum pre-training heterogeneous subgraph transformer for op-n recommendation,” arXio preprint arXio:2106.06722, 2021.
[71] X. Zhou, A. Sun, Y. Liu, J. Zhang, and C. Miao, "Selfcf: A sim- A ple framework for self-supervised collaborative filtering," arXiv preprint ar Xio:2107.03019, 2021.
[72] B. Hao, H. Yin, J. Zhang, C. Li, and H. Chen, "A multi-strategy based pre-training method for cold-start recommendation," arXiu preprint arXiv:2112.02275, 2021.
[73I Y. Yang, L. Wu, R. Hong, K. Zhang, and M. Wang, "Enhanced graph leaming for collaborative filtering via mutual information maximization," in SIGIR, 2021, pp. 71-80.
[74] H. Yang, H. Chen, L. Li, S. Y. Philip, and G. Xu, "Hyper meta- path contrastive learning for multi-behavior recommendation," in ICDM. IEEE, 2021, pp. 787-796.
[75] J. Cao, X. Lin, S. Guo, L. Liu, T. Liu, and B. Wang, "Bipartite graph embedding via mutual information maximization,” in WSDM, 2021, pp.635-643.
[76] R. Xie, Q. Liu, L. Wang, S. Liu, B. Zhang, and L. Lin, "Contrastive cross-domain recommendation in matching, arXiw preprint arXiu:2112.00999, 2021.
[77] C. Wang, Y. Liang, Z. Liu, T. Zhang, and P. S. Yu, "Pre-training graph neural network for cross domain recommendation,” arXiv preprint arXio:2111.08268, 2021. 178] I. Yao, X. Yi, D. Z. Cheng, F. Yu, T. Chen, A. Menon, L. Hong,E. H. Chi, S. Toa, J. Kang et al., "Self-supervised learing for large scale item recommendations," in CIKM, 2021, Pp. 4321-4330.
[79] R. Qiu, Z. Huang, H. Yin, and Z. Wang, Contrastive learning for representation degeneration problem in sequential recommenda- tion,” in WSDM. ACM, 2022, Pp. 813-823.
[80] Z. Liu, Y. Chen, J. Li, M. Luo, S. Y. Philip, and C. Xiong, “Self- supervised learning for sequential recommendation with model augmentation,” 2021.
[81] Z. Xie, C. Liu, Y. Zhang, H. Lu, D. Wang, and Y. Ding, “Ad- versarial and contrastive variational autoencoder for sequential recommendation,” in WWW, 2021, pp. 449–459.
[82] Y. Chen, Z. Liu, J. Li, J. McAuley, and C. Xiong, “Intent con- trastive learning for sequential recommendation,” arXiv preprint arXiv:2202.02519, 2022.
[83] Z. Lin, C. Tian, Y. Hou, and W. X. Zhao, “Improving graph collaborative filtering with neighborhood-enriched contrastive learning,” arXiv preprint arXiv:2202.06200, 2022.
[84] J. Li, P. Zhou, C. Xiong, and S. C. Hoi, “Prototypical con- trastive learning of unsupervised representations,” arXiv preprint arXiv:2005.04966, 2020.
[85] T. Huang, Y. Dong, M. Ding, Z. Yang, W. Feng, X. Wang, and J. Tang, “Mixgcf: An improved training method for graph neural network-based recommender systems,” 2021.
[86] Y. Kalantidis, M. B. Sariyildiz, N. Pion, P. Weinzaepfel, and D. Larlus, “Hard negative mixing for contrastive learning,” in NeurIPS 2020, 2020.
[87] X. He, K. Deng, X. Wang, Y. Li, Y. Zhang, and M. Wang, “Light- gcn: Simplifying and powering graph convolution network for recommendation,” in SIGIR. ACM, 2020, pp. 639–648.
[88] S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-Thieme, “Bpr: Bayesian personalized ranking from implicit feedback,” in
UAI. AUAI Press, 2009, pp. 452–461.
[89] Z. Liu, Y. Ma, Y. Ouyang, and Z. Xiong, “Contrastive learning for recommender system,” arXiv preprint arXiv:2101.01317, 2021.
[90] H. Yin, Q. Wang, K. Zheng, Z. Li, J. Yang, and X. Zhou, “Social influence-based group representation learning for group recom- mendation,” in ICDE. IEEE, 2019, pp. 566–577.
[91] P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, “Graph attention networks,” in ICLR, 2018.
[92] K. Xu, W. Hu, J. Leskovec, and S. Jegelka, “How powerful are graph neural networks?” in ICLR, 2019.
[93] Y. Koren, R. M. Bell, and C. Volinsky, “Matrix factorization techniques for recommender systems,” IEEE Computer, vol. 42, no. 8, pp. 30–37, 2009.
[94] C. Wang, W. Ma, and C. Chen, “Sequential recommendation with multiple contrast signals,” ACM TOIS, 2022.
[95] D. Cai, S. Qian, Q. Fang, J. Hu, W. Ding, and C. Xu, “Het- erogeneous graph contrastive learning network for personalized micro-video recommendation,” IEEE Transactions on Multimedia, 2022.
[96] J. Yu, M. Gao, J. Li, H. Yin, and H. Liu, “Adaptive implicit friends identification over heterogeneous network for social recommen- dation,” in CIKM. ACM, 2018, pp. 357–366.
[97] J. Yu, M. Gao, H. Yin, J. Li, C. Gao, and Q. Wang, “Generating reliable friends via adversarial training to improve social recom- mendation,” in ICDM. IEEE, 2019, pp. 768–777.
[98] X. Long, C. Huang, Y. Xu, H. Xu, P. Dai, L. Xia, and L. Bo, “So- cial recommendation with self-supervised metagraph informax network,” in CIKM, 2021, pp. 1160–1169.
[99] W. Guo, C. Zhang, Z. He, J. Qin, H. Guo, B. Chen, R. Tang, X. He, and R. Zhang, “Miss: Multi-interest self-supervised learn- ing framework for click-through rate prediction,” arXiv preprint arXiv:2111.15068, 2021.
[100] T. Gao, X. Yao, and D. Chen, “Simcse: Simple contrastive learning of sentence embeddings,” arXiv preprint arXiv:2104.08821, 2021.
[101] J. Yu, H. Yin, X. Xia, L. Cui, and Q. V. H. Nguyen, “Graph augmentation-free contrastive learning for recommendation,” arXiv preprint arXiv:2112.08679, 2021.
[102] Z. Liu, Y. Chen, J. Li, M. Luo, S. Y. Philip, and C. Xiong, “Self- supervised learning for sequential recommendation with model augmentation,” 2021.
[103] W. Wei, C. Huang, L. Xia, Y. Xu, J. Zhao, and D. Yin, “Contrastive meta learning with behavior multiplicity for recommendation,” in Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, 2022, pp. 1120–1128.
[104] Y. Wu, R. Xie, Y. Zhu, X. Ao, X. Chen, X. Zhang, F. Zhuang, L. Lin, and Q. He, “Multi-view multi-behavior contrastive learning in recommendation,” arXiv preprint arXiv:2203.10576, 2022.
[105] S. Nowozin, B. Cseke, and R. Tomioka, “f-gan: Training genera- tive neural samplers using variational divergence minimization,” NeurIPS, vol. 29, 2016.
[106] M. 1. Belghazi, A. Baratin, S. Rajeshwar, S. Ozair, Y. Bengio, A. Courville, and D. Helm, "Mutual information neural estima- tion〞 in ICML. PMLR, 2018, pp. 531-540.
[107] R. D. Hjelm, A. Fedorov, S. Lavoie-Marchildon, K. Grewal, P. Bachman, A. Trischler, and Y. Bengio, "Learning deep repre- sentations by mutual information estimation and maximization,” arXiu preprint arXio:1808.06670, 2018.
[108] M. Gutmann and A. Hyvarinen, "Noise-contrastive estimation: A new estimation principle for unnormalized statistical models,” in AISTATS. JMLR Workshop and Conference Proceedings, 2010, PP. 297-304.
[109] T. Wang and P. Isola, "Understanding contrastive representation learning through alignment and uniformity on the hypersphere,”" in ICML. PMLR, 2020, pp. 9929-9939.
[1101 J. Wu, X. Wang, X. Gao, J. Chen, H. Fu, T. Qiu, and X. He, ”On the effectiveness of sampled softmax loss for item recommendation,” arXiu preprint arXiv:2201.02327, 2022.
[111] F. Wang and H. Liu, "Understanding the behaviour of contrastive loss, in CVPR, 2021, pp. 2495-2504.
[112] P. Khosla, P Teterwak, C. Wang, A. Sarna, Y. Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, "Supervised contrastive learing,” NeurlPS, vol. 33, pp. 18 661-18 673, 2020.
[113] W.-C. Kang and J. McAuley, "Self-attentive sequential recommen- dation,” in ICDM. IEEE, 2018, Pp. 197-206.
[1141 Q. Zhang, J. Li, Q. Jia, C. Wang, J. Zhu, Z. Wang, and X. He, "Unbert: User-news matching bert for news recommendation,” in ICAl, 2021, pp. 3356-3362.
[115] C. Wu, F. Wu, T. Qi, and Y. Huang, "Empowering news recom- mendation with pre-trained language models,” in SIGIR, 2021, PP. 1652-1656.
[116] z. Qiu, X. Wu, J. Gao, and W. Fan, “U-bert: Pre-training user representations for improved recommendation," in AAAI, 2021, pp. 1-8.
[117] F. Yuan, X. He, H. Jiang, G. Guo, J. Xiong, Z. Xu, and Y. Xiong, "Future data helps training: Modeling future contexts for session- based recommendation,” in WWw, 2020, pp. 303-313.
[1181 C. Xiao, R. Xie, Y. Yao, Z. Liu, M. Sun, X. Zhang, and L. Lin, "Up- rec: User-aware pre-training for recommender systems,” arXio preprint arXio:2102.10989, 2021.
[119] F. Yuan, X. He, A. Karatzoglou, and L. Zhang, "Parameter- efficient transfer from sequential behaviors for user modeling and recommendation,” in SIGIR, 2020, PP. 1469-1478.
[120] K. Shin, H. Kwak, K. M. Kim, M. Kim, Y.-J. Park, J. Jeong, and S. Jung, "One4all user representation for recommender systems in e-commerce,” arXiu preprint arXio:2106.00573, 2021.
[121] J. Shang, T. Ma, C. J. Xiao, and J. Sun, "Pre-training of graph augmented transformers for medication recommendation,” arXio preprint arXio:1906.00346, 2019.
[1221 Y. Liu, S. Yang, C. Lei, G. Wang, H. Iang, J. Zhang, A. Sun, and C. Miao, "Pre-training graph transformer with multimodal side information for recommendation,” in ACM Multimedia, 2021, Pp. 2853-2861.
[123] J. Ma, C. Zhou, H. Yang, P. Cui, X. Wang, and w. Zhu, “Disen- tangled self-supervision in sequential recommenders,” in KDD, 2020, Pp. 483-491.
[124] B. Hao, J. Zhang, H. Yin, C. Li, and H. Chen, "Pre-training graph neural networks for cold-start users and items representation," in WSDM, 2021, Pp. 265-273.
[125] J. Zhang, B. Bai, Y. Lin, J. Liang, K. Bai, and F. Wang, "General- purpose user embeddings based on mobile app usage,” i KDD, 2020, PP. 2831-2840.
[126] B. Zoph, G. Ghiasi, T.-Y. Lin, Y. Cui, H. Liu, E. D. Cubuk, and Q. Le, "Rethinking pre-training and self-training,” NeurlPs, vol 33, Pp. 3833-3845, 2020.
[127] Z. Liu, Z. Fan Y. Wang, and P. S. Yu, ”Augmenting sequential rec- ommendation with pseudo-prior items via reversely pre-training transformer,” in SIGIR, 2021, Pp. 1608-1612.
[128] J.Jiang, Y. Luo, 丁 B. Kim, K. Zhang, and S. Kim, "Sequential recommendation with bidirectional chronological augmentation of transformer,” arXiu preprint arXiv:2112.06460, 2021.
[129] A. Blum and T. Mitchell, ”Combining labeled and unlabeled data with co-training,” in CLOr, 1998, Pp. 92-100.
[130] H. Chen, H. Yin, T. Chen, Q. V. H. Nguyen, W.-C. Peng, and X. Li, "Exploiting centrality information with graph convolutions for network representation learing, in ICDE. IEEE, 2019, Pp. 590-601.
[131] C. Wu, F. Wu, T. Qi, J. Lian, Y. Huang, and X. Xie, “PTUM: pre-training user model from unlabeled user behaviors via self- supervision,” in EMNLP, 2020.
[132] H. Liu, D. Tang, J. Yang, X. Zhao, J. Tang, and Y. Cheng, "Self- supervised learing for alleviating selection bias in recommen- dation systems,” 2021.
[133] M. Ma, P. Ren, Z. Chen, Z. Ren, H. Liang, J. Ma, and M. de Ri- ike, "Improving transformer-based sequential recommenders through preference editing,” arXiu preprint arXio:2106.12120, 2021.
[134] Y. Tao, M. Gao,J. Yu, Z. Wang,Q. Xiong, and X. Wang, "Predictive and contrastive: Dual-auxiliary learning for recommendation,”" arXiu preprint arXiv:2203.03982, 2022.
[135] J. Ma, C. Zhou, P. Cui, H. Yang, and W. Zhu, "Learning disen- tangled representations for recommendation," NewrlPS, vol. 32, 2019.
[136] Y. Bengio, J. Louradour, R. Collobert, and J. Weston, "Curriculum learing,” in ICML, 2009, pp. 41-48.
[137] Z.-H. Zhou and M. Li, “Tri-training: Exploiting unlabeled data using three classifiers,” IEEE TKDE, vol. 17, no. 11, Pp. 1529- 1541, 2005.
[138] M. Kim, J. Tack, and S. J. Hwang, "Adversarial self-supervised contrastive learning,” NeurlPS, vol. 33, Pp. 2983-2994, 2020.
[139] J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi, “Modeling task relationships in multi-task learing with multi-gate mixture- of-experts,〞 in KDD, 2018, PP 1930-1939.
[1401 W. X. Zhao, S. Mu, Y. Hou,z. Lin, Y. Chen, X. Pan, K. Li, Y. Lu, H. Wang, C. Tian et al., "Recbole: Towards a unified, comprehen- sive and efficient framework for recommendation algorithms,” in CIKM, 2021, Pp. 4653-4664.
[141] T. Xiao, X. Wang, A. A. Efros, and T. Darrell, "What should not be contrastive in contrastive learning,” in ICLR, 2021.
[142] 7. Wang, M. Gao,J. Ti,J. Thang, and J. Thong, "Gray-hox shilling attack: An adversarial learning approach,” ACM TIST, 2022.
[143] H. Zhang, C. Tian, Y. Li, L. Su, N. Yang, W. X. Zhao, and J. Gao, “Data poisoning attack against recommender system using in- complete and perturbed data,” in KDD, 2021, pp.2154-2164.
[144] A. Saha, A. Tejankar, S. A. Koohpayegani, and H. Pirsiavash, "Backdoor attacks on self-supervised learning,” ar Xiu preprint ar Xiv:2105.10123, 2021.
[145] S. Zhang, H. Chen, X. Sun, Y. Li, and G. Xu, " Unsupervised graph poisoning attack via contrastive loss back-propagation,” arXiu preprint arXiv:2201.07986, 2022.
[146] Q. Wang, H. Yin, T. Chen, J. Yu, A. Zhou, and X. Zhang, “Fast-adapting and privacy-preserving federated recommender system,” The VLDB Journal, pp. 1-20,, 2021.
[147] Q. Wang, H. Yin, T. Chen, Z. Huang, H. Wang, Y. Zhao, and N. Q. Viet Hung, "Next point-of-interest recommendation on resource- constrained mobile devices,” in Www, 2020, pp. 906-916.
[148] Y. Yu, F. Wu, C. Wu, J. Yi, T. Qi, and Q. Liu,“ Tiny-newsrec: Efficient and effective plm-based news recommendation,” arXio preprint arXiv:2112.00944, 2021.
[149] Y. Wang, Y. Zhang, and M. Coates, "Graph structure aware contrastive knowledge distillation for incremental learning in recommender systems," in CIKM, 2021, pp. 3518-3522.
[150] L Huang, Y. Liu, X. Zhou, A. You, M. Li, B. Wang, Y. Zhang, P. Pan, and X. Yinghui, "Once and for all: Self-supervised multi- modal co-training on one-billion videos at alibaba,” in ACM MM, 2021, pp. 1148-1156.

Comments | NOTHING