摘要
虽然深度学习和深度强化学习 (RL) 系统在图像分类、游戏和机器人控制等领域取得了令人印象深刻的成果,但数据效率仍然是一个重大挑战。多任务学习已成为跨多个任务共享结构以实现更高效学习的有前途的方法。然而,多任务设置带来了许多优化挑战,与独立学习任务相比,很难实现巨大的效率提升。与单任务学习相比,多任务学习如此具有挑战性的原因尚不完全清楚。在这项工作中,我们确定了多任务优化环境中导致有害梯度干扰的一组三个条件,并开发了一种简单而通用的方法来避免任务梯度之间的这种干扰。我们提出了一种梯度手术的形式,将任务的梯度投影到具有冲突梯度的任何其他任务的梯度的法线平面上。在一系列具有挑战性的多任务监督和多任务强化学习问题上,这种方法可以显着提高效率和性能。此外,它与模型无关,可以与先前提出的多任务架构相结合以增强性能。
引言
虽然深度学习和深度强化学习 (RL) 在使系统学习复杂任务方面显示出巨大的前景,但当前方法的数据要求使得学习广泛的功能变得困难,特别是当所有任务都是从头开始单独学习时。解决此类多任务学习问题的一种自然方法是联合训练所有任务的网络,目的是发现跨任务的共享结构,从而比单独解决任务实现更高的效率和性能。然而,同时学习多个任务的结果是一个困难的优化问题,与单独学习任务相比,有时会导致整体性能和数据效率更差
尽管在多任务学习方面已有大量研究
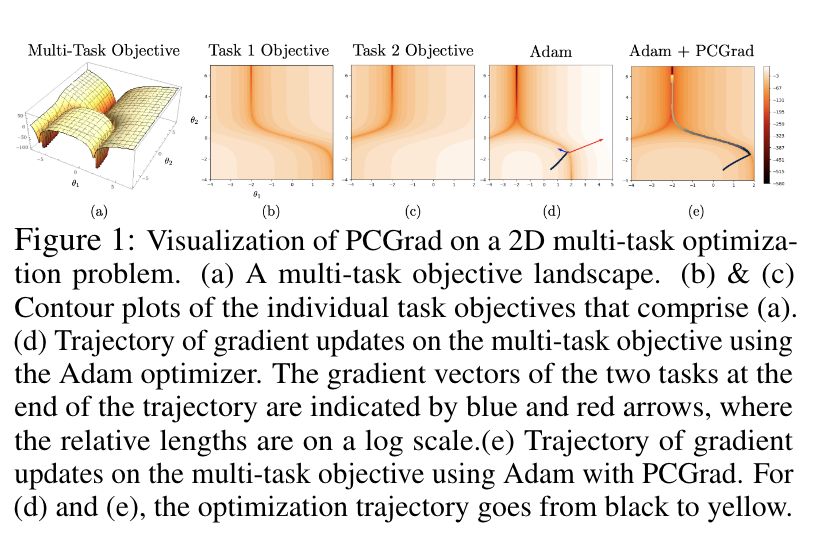
作为说明性示例,请考虑图 1a-c 中两个任务目标的 2D 优化场景。每个任务的优化景观都由一个深谷组成,这是在神经网络优化景观中观察到的一种特性[22],每个山谷的底部具有高正曲率和任务梯度大小差异大的特点。在这种情况下,多任务梯度由一个任务梯度主导,这是以降低另一任务的性能为代价的。此外,由于高曲率,主导任务的改进可能被高估,而非主导任务的性能下降可能被低估。因此,优化器很难在优化目标上取得进展。在图 1d)中,优化器到达任务 1 的深谷,但无法在存在梯度冲突、高曲率和梯度大小差异较大的参数设置中穿越深谷(参见图 1d 中绘制的梯度) )。在5.3节中,我们通过实验发现这种悲惨三合会也发生在高维神经网络多任务学习问题中。
这项工作的核心贡献是一种通过直接改变梯度来减轻梯度干扰的方法,即通过执行“梯度手术”。如果两个梯度发生冲突,我们可以通过将每个梯度投影到另一个梯度的法线平面上来改变梯度,从而防止梯度的干扰分量应用于网络。我们将这种特殊形式的梯度手术称为投影冲突梯度(PCGrad)。 PCGrad 与模型无关,只需要对梯度应用进行一次修改。因此,它很容易应用于一系列问题设置,包括多任务监督学习和多任务强化学习,并且还可以很容易地与其他多任务学习方法相结合,例如那些修改架构的方法。我们从理论上证明了 PCGrad 在标准多任务梯度下降的基础上进行改进的局部条件,并且我们在各种具有挑战性的问题上对 PCGrad 进行了实证评估,包括多任务 CIFAR 分类、多目标场景理解、具有挑战性的多任务 RL 领域以及目标条件强化学习。总的来说,我们发现与之前的方法相比,PCGrad 在数据效率、优化速度和最终性能方面带来了显着的改进,包括在多任务强化学习问题上的绝对改进超过 30 %。此外,在多任务监督学习任务上,PCGrad 可以成功地与先前最先进的多任务学习方法相结合,以获得更好的性能。
使用 PCGrad 进行多任务学习
虽然原则上可以通过简单地应用标准单任务算法以及为模型提供合适的任务标识符或简单的多头或多输出模型来解决多任务问题,但许多先前的工作
预备知识:问题和符号
多任务学习的目标是找到模型
悲剧三重奏:冲突梯度、主导梯度、高曲率
我们假设多任务学习中的一个关键优化问题源于冲突的梯度,其中不同任务的梯度通过负内积来衡量彼此远离。然而,冲突的梯度本身并没有什么害处。事实上,简单地平均任务梯度应该提供正确的解决方案来降低多任务目标。然而,在某些情况下,这种相互冲突的梯度会导致性能显着下降。考虑一个双任务优化问题。如果一个任务的梯度比另一个任务的梯度大得多,它将主导平均梯度。如果沿任务梯度方向也存在较高的正曲率,则主导任务的性能改进可能会被显着高估,而主导任务的性能下降可能会被显着低估。因此,我们可以将三种条件的共现描述如下:(a)当多个任务的梯度相互冲突时(b)当梯度幅度差异很大时,导致某些任务梯度支配其他任务梯度,以及(c) 当多任务优化场景中存在高曲率时。我们正式定义以下三个条件。
定义1.我们将
定义2.我们将两个梯度
定义3. 我们将多任务曲率定义为
当
我们的目的是研究悲剧三合会,并通过两个例子来观察这三种情况的存在。首先,考虑图 1a 所示的二维优化景观,其中每个任务目标的景观对应于一个曲率较大的深而弯曲的山谷(图 1b 和 1c)。这个多任务目标的最优值对应于两个山谷的交汇处。有关优化景观的更多详细信息,请参阅附录 D。该优化景观的特定点表现出所描述的三个条件,并且我们观察到,Adam [30] 优化器精确地在这些点之一处停止(见图 1d),从而阻止了它从达到最佳状态。这为我们的假设提供了一些经验证据。我们在 5.3 节中的实验进一步表明这种现象发生在深度网络的多任务学习中。受这些观察的启发,我们开发了一种算法,旨在减轻由冲突梯度、主导梯度和高曲率引起的优化挑战,我们接下来将对此进行描述。
PCGrad:项目冲突的梯度
我们的目标是通过直接改变梯度本身来防止冲突,从而打破悲剧三元组的一个条件。在本节中,我们概述了改变梯度的方法。在下一节中,我们将从理论上证明,当存在主导梯度和高曲率时,消除梯度冲突可以有利于多任务学习。
为了最大程度地有效和广泛适用,我们的目标是以允许任务梯度之间积极相互作用的方式改变梯度,并且不引入对模型形式的假设。因此,当梯度不冲突时,我们不会改变梯度。当梯度发生冲突时,PCGrad 的目标是修改每个任务的梯度,以最大限度地减少与其他任务梯度的负面冲突,从而缓解高曲率引起的低估和高估问题。
为了在优化过程中消除梯度冲突,PCGrad 采用了一个简单的过程:如果两个任务之间的梯度发生冲突,即它们的余弦相似度为负,我们将每个任务的梯度投影到另一个任务梯度的法线平面上。这相当于消除了任务梯度的冲突部分,从而减少了任务之间破坏性梯度干扰的量。这个想法的图形描述如图 2 所示
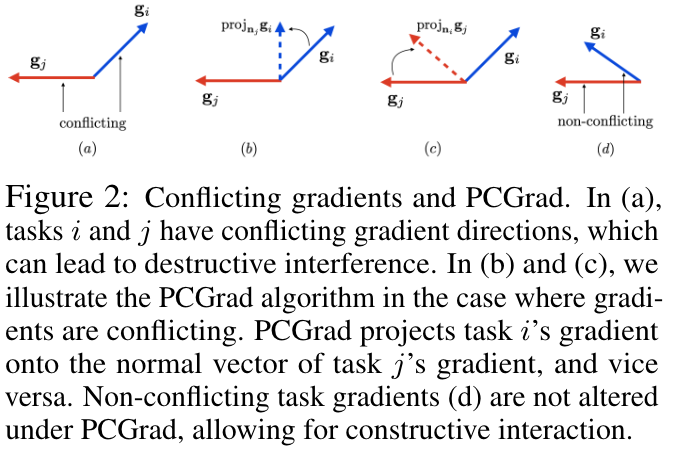
假设任务

这个过程虽然实现起来很简单,但可以确保我们为每个批次的每个任务应用的梯度对批次中的其他任务的干扰最小,从而减轻冲突的梯度问题,在多任务中产生标准一阶梯度下降的变体。目标设定。在实践中,PCGrad 可以与任何基于梯度的优化器结合使用,包括常用的方法,例如带有动量的 SGD 和 Adam [30],只需将计算出的更新而不是原始梯度传递给相应的优化器即可。我们的实验结果验证了这个过程减少了梯度冲突问题的假设,并发现学习进度因此得到了显着提高。
PCGrad 的理论分析
PCGrad 实践
我们在具有多个任务或目标的监督学习和强化学习问题中使用 PCGrad。在这里,我们讨论 PCGrad 在这些设置中的实际应用。
在多任务监督学习中,每个任务
对于多任务强化学习和目标条件强化学习,PCGrad 可以很容易地应用于策略梯度方法,按照算法 1,直接更新每个任务的计算策略梯度,类似于监督学习设置。对于演员-评论家算法,应用 PCGrad 也很简单:我们只需将演员和评论家的任务梯度替换为通过 PCGrad 计算的梯度。有关 RL 实际实施的更多详细信息,请参阅附录 C。

Comments | NOTHING