ACG2vec系列之ACGVoc2vec——基于深度学习的二次元场景适应的文本特征抽取器
Huggingface在线体验:https://huggingface.co/OysterQAQ/ACGVoc2vec
github主仓库地址(tensorflow的savemodel格式可以在release中下载):https://github.com/OysterQAQ/ACG2vec
模型结构为sentence-transformers,使用distiluse-base-multilingual-cased-v2预训练权重,以5e-5的学习率在动漫相关语句对数据集下进行微调,损失函数为MultipleNegativesRankingLoss。
模型输入文本,输出512维的特征向量,可以用于标签推荐,文本搜索等直接下游任务,也可以作为文本特征抽取器来组合进解决其他任务的模型。
数据集主要包括:
-
Bangumi
- 动画日文名-动画中文名
- 动画日文名-简介
- 动画中文名-简介
- 动画中文名-标签
- 动画日文名-角色
- 动画中文名-角色
- 声优日文名-声优中文名
-
pixiv
- 标签日文名-标签中文名
-
AnimeList
- 动画日文名-动画英文名
-
维基百科
- 动画日文名-动画中文名
- 动画日文名-动画英文名
- 中英日详情页h2标题及其对应文本
- 简介多语言对照(中日英)
- 动画名-简介(中日英)
-
moegirl
- 动画中文名的简介-简介
-
动画中文名+小标题-对应内容
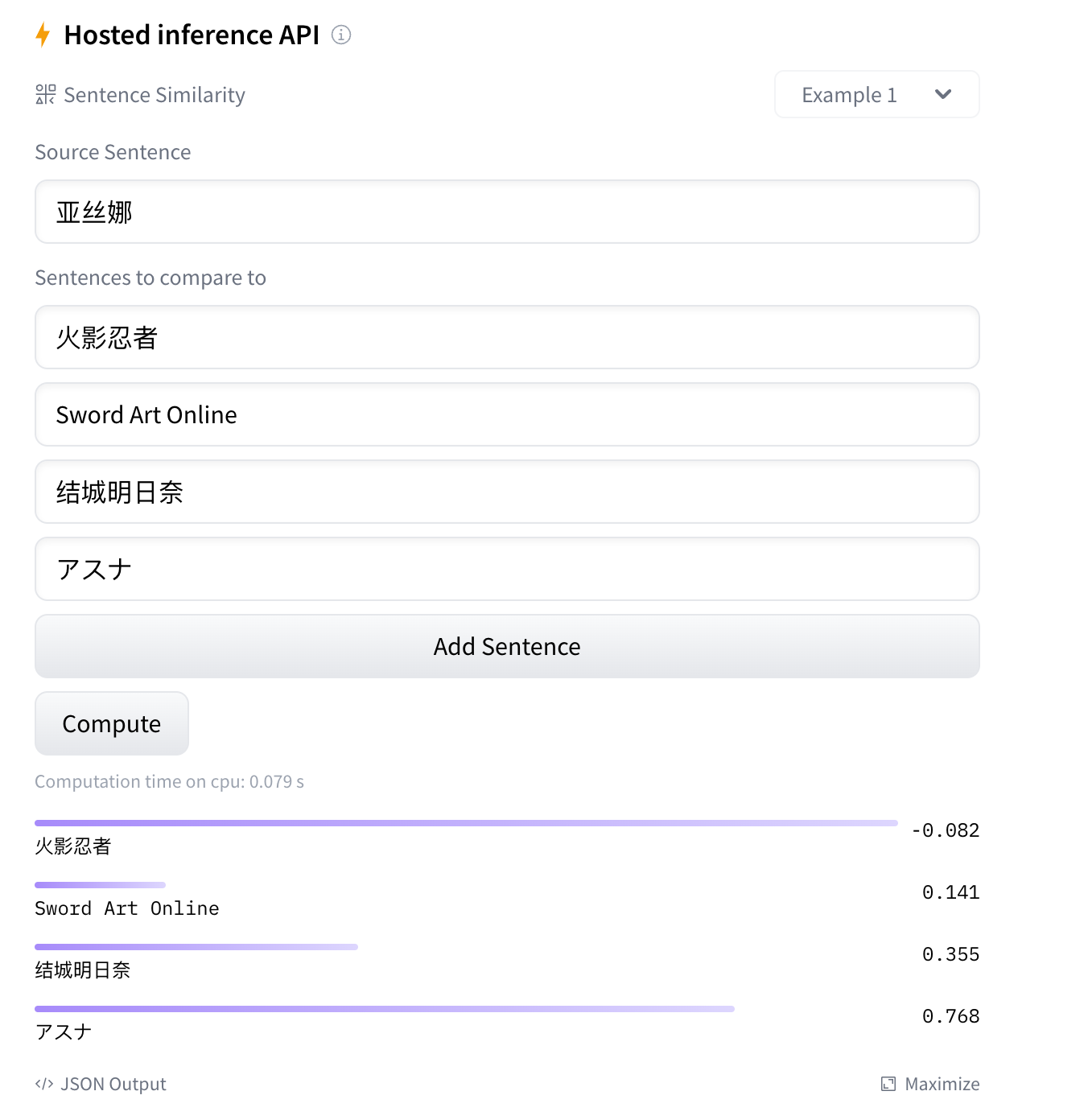
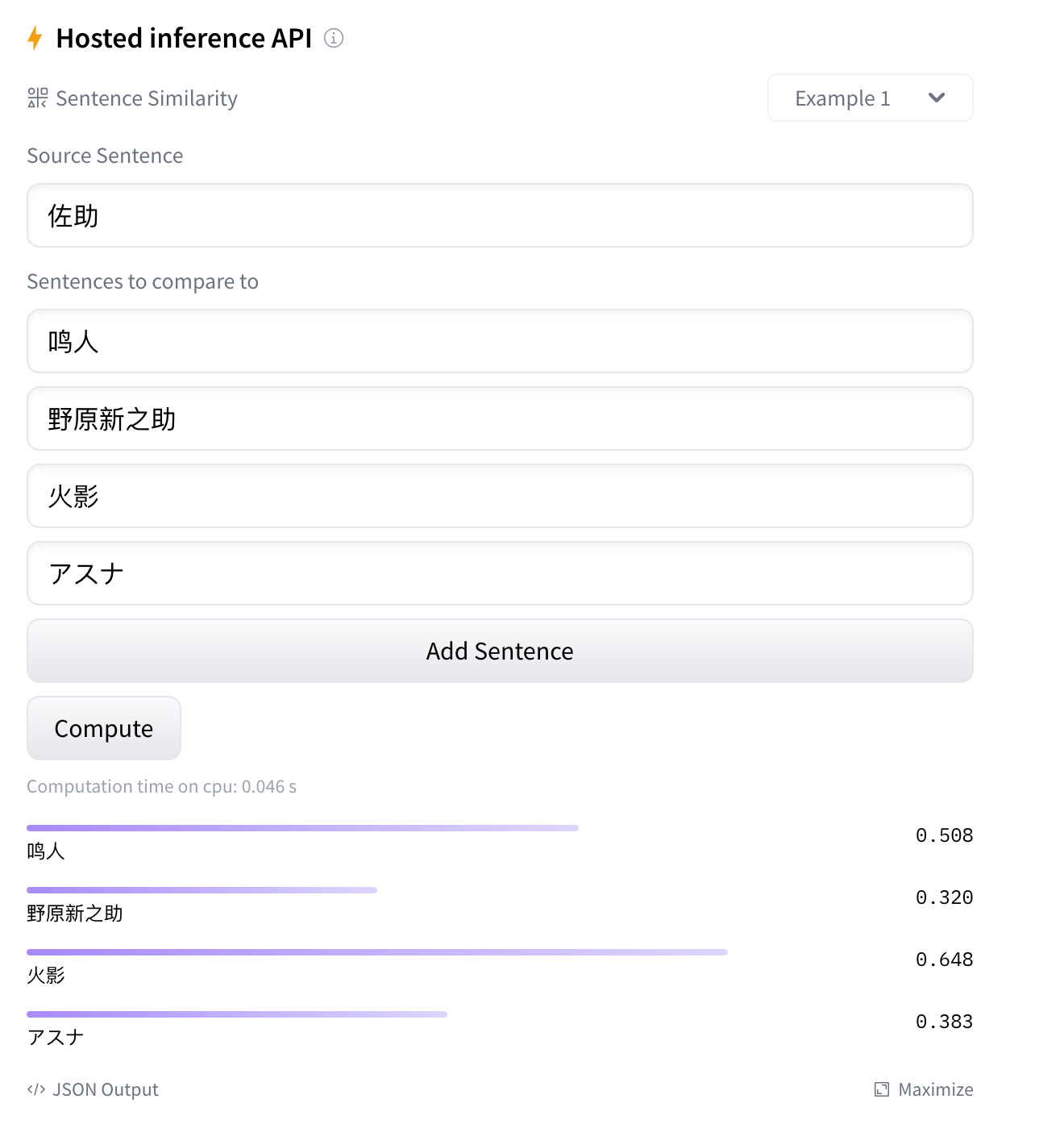
在进行爬取,清洗,处理后得到8000w对文本对(还在持续增加),batchzise=80训练了20个epoch,使st的权重能够适应该问题空间,生成融合了领域知识的文本特征向量(体现为有关的文本距离更加接近,例如作品与登场人物,或者来自同一作品的登场人物)。
效果预览(分数为文本特征向量之间的距离):

Comments | NOTHING