概述
其中
设计目的是使当query
从softmax说起
对于多分类问题,设类别标签
其中
在数学,尤其是概率论和相关领域中,归一化指数函数,或称Softmax函数,是逻辑函数的一种推广。它能将一个含任意实数的
交叉熵
因为softmax本身不带有可学习的参数,因此在深度学习框架中通常和一些激活函数被同等的看待。模型结构上,多分类问题与二分类问题在预测头(最后一层全连接)的差异通常在其激活函数是使用softmax还是sigmoid。而在损失函数上,二分类问题常用二元交叉熵函数,多分类问题常用交叉熵函数。
交叉熵损失函数(Cross-Entropy Loss Function)一般用于分类问题.假设样本的标签
其中的
将softmax带入交叉熵,得
由于ground truth
可以看到已经和Info NCE的公式大体接近。
NCE
如果将对比学习看成多分类问题 正样本和所有的负样本都看成不同的类会导致有上百万的类,导致计算问题。NCE(noise contrastive estimation)核心思想是将多分类问题转化成二分类问题,一个类是数据类别 data sample,另一个类是噪声类别 noisy sample,通过学习数据样本和噪声样本之间的区别,将数据样本去和噪声样本做对比,也就是“噪声对比(noise contrastive)”,从而发现数据中的一些特性。但是,如果把整个数据集剩下的数据都当作负样本(即噪声样本),虽然解决了类别多的问题,计算复杂度还是没有降下来,解决办法就是做负样本采样来计算loss,这就是estimation的含义,也就是说它只是估计和近似。一般来说,负样本选取的越多,就越接近整个数据集,效果自然会更好。
Info NCE
Info NCE loss是NCE的一个简单变体,它认为如果你只把问题看作是一个二分类,只有数据样本和噪声样本的话,可能对模型学习不友好,因为很多噪声样本可能本就不是一个类,因此还是把它看成一个多分类问题比较合理(但这里的多分类k指代的是负采样之后负样本的数量,下面会解释)。于是就有了InfoNCE loss,公式如下:
上式中,
温度系数的作用
温度系数
如果温度系数设的越大,logits分布变得越平滑,那么对比损失会对所有的负样本一视同仁,导致模型学习没有轻重。如果温度系数设的过小,则模型会越关注特别困难的负样本,但其实那些负样本很可能是潜在的正样本,这样会导致模型很难收敛或者泛化能力差。
总之,温度系数的作用就是它控制了模型对负样本的区分度。
联系本文
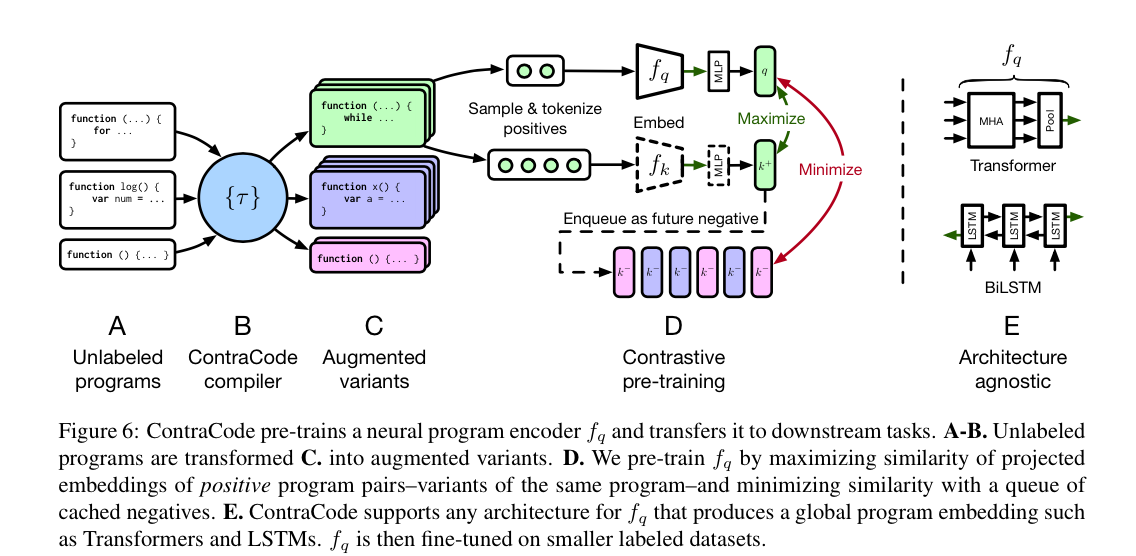
运用在《Contrastive Code Representation Learning》中也没什么不同,仅仅只是正负样本的生成变化,以及从图像到代码,对比学习中数据预处理和具体编码器结构发生了变化。该论文使用使用Info NCE作为损失函数来优化,试图使经过数据增强后的代码与原代码的表征向量更为接近,而与其他不同语义的代码的表征向量更为疏远,使用对比学习为代码学习到了一个泛化性较好且带有语义信息的稳健分布式表示(特征向量)。
参考
[1] Momentum Contrast for Unsupervised Visual Representation Learning.

Comments | 2 条评论
… 博主
这是在写论文吗
生蚝Babe 博主
@...
只是一门课的作业